chukcha
Easy to use distributed event bus similar to Kafka.
The event bus is designed to be used as a persistent intermediate storage buffer for any kinds of events or logs that you might want.
Possible usages for Chukcha are basically the same as for Kafka, including, but not limited to:
- Centralised logs collection,
- Collecting structured or unstructured events for machine learning or analytics (e.g. Hadoop, ClickHouse, etc),
- Change log buffer to synchronise the contents of one or more storages with each other (e.g. update a full-text index upon database update).
The messages are expected to be delimited by a new line character, although there are no other limitations in terms of events format: it can be JSON, plain text, Protobuf (with \ and new line character escaped), etc.
The youtube playlist to see live development: https://www.youtube.com/watch?v=t3FdULDRfRM&list=PLWwSgbaBp9XqeuIuTWqpNtvf_EL0I4TJ2
Requirements
Go 1.16+ is needed to build Chukcha.
Features (work in progress)
- Easy to configure out of the box to not lose data unexpectedly.
- Distributed, with asynchronous replication by default.
- Explicit acknowledgement of data that was read.
Limitations
- The maximum supported size is 1 MiB per message.
- Each message has to be separated by a new line character (
\n). - The maximum default write batch size is 4 MiB.
- Maximum memory consumption is around
(write batch size) * 2(8 MiB with default settings) per connection. TODO: memory consumption per connection can be brought down significantly if using a custom protocol on top of HTTP. - The default upper bound for the number of open connections is 262144.
- Kafka protocol is not likely to be ever supported unless someone decides to contribute it.
Differences to Kafka
Compared to Kafka, Chukcha does not guarantee that the messages will be delivered in order or exactly once. You can come close to getting a total order of messages if you always write a single instance, but in that case if that instance fails there would be no way of knowing whether or not data was actually flushed to disk and/or replicated so you would have to retry sending the message to another node in the cluster, so messages can be duplicated. Arguably, the same applies to Kafka, however Kafka provides much stricter guarantees by basically forcing you to always write to the partition leader instead of a random node. Since there is no such concept as a partition leader in Chukcha and all nodes are equal, achieving total messages order is much more difficult.
In Chukcha you are encouraged to spread the write and read load across all the nodes in Chukcha cluster so events order will not be preserved because of async replication being the default. Also please keep in mind that in order to achieve the best performance you would probably want to write data in batches and not just write a single message at a time, so because of that events from every client will need to be buffered and there will be no total event order in that case either. You can see the illustration below that covers this.

Handling data duplication and not having a strict order of events
In many situations duplicating data (or losing it entirely) in case of errors is OK and you don't need to do anything special about that scenario. However, in many cases it actually does matter and the clients need to be able to handle it. Even if you think you don't have that problem in Kafka you probably just lose data instead of having duplicates, which is not ideal in many situations either. In Kafka it's actually possible to both lose data and have duplicates and out-of-order events too in the presence of failures if you are not careful!
Idempotent events handling in databases
Basically the solution to both data being duplicated and loose order of events is the same: idempotency. For example, in the data duplication scenario above you don't want to send just an event that "something happened", you also want to attach a unique event ID to each event that you are sending. When processing each event, e.g. recording it to a database, you then make sure that in a single transaction you first make sure that you haven't processed that event before, e.g. by using a separate table for that, and then doing the actual processing.
Idempotent full-text indexing (e.g. updating Elastic or Manticore Search index)
If you are doing things that are idempotent by nature, e.g. indexing documents, make sure to only send events like "entity with ID changed" and not the entity contents. This way you would have to fetch the most recent contents of that entity from your persistent storage when processing the event and thus you always have up-to-date index. Otherwise you can end up in a situation when the newer versions of the entity are processed before the older ones (this can happen e.g. if you manage to read events that were sent to two different Chukcha nodes at different times) and having a stale index instead. Make sure to update the persistent storage before sending an indexing event too.
Idempotent analytics (e.g. in ClickHouse)
If you are using e.g. ClickHouse make sure you are using e.g. a *ReplacingMergeTree engine family and collapse events by a unique event id generated in your client when sending the event so that duplicates are removed when doing merges.
Idempotent sending of e-mails
There is no such thing as sending e-mail idempotently. You would have to resort to keeping track of e-mails that you already sent successfully in a separate database and have a small chance of sending the last e-mail in the queue more than more once in case of failures. You can limit the number of attempts by consulting the database both before and after attempting to send an e-mail and e.g. limit the number of attempts before giving up on that particular entry.
Data loss scenarios
By default the data is not flushed to disk upon each write, but this can be changed in the server config or per request.
The data durability guarantees are thus the following:
By default data written to a single node can be lost, if:
- The machine was not shut down cleanly, e.g. a kernel panic occurred or a host experienced any other hardware failures, or
- The machine was completely lost and never returned into the cluster
(TODO): When min_sync_replicas is greater than 0, data will only be lost if:
- More than the
min_sync_replicasmachines are not shut down cleanly simultaneously, or - More than
min_sync_replicasmachines are lost completely and never returned to the cluster.
(TODO2): When sync_each_write=true is set
- Data is only lost when machine's hard drives/SSDs fail.
(TODO2): When both sync_each_write=true and min_sync_replicas > 0
- Data is only lost if more than
min_sync_replicasmachines are totally lost and never re-join the cluster.
Design (work in progress)
- Data is split into chunks and is stored as files on disk. Each server owns the chunks being written into and the ownership of each individual chunk is never changed. The files are replicated to all other servers in the cluster.
- Readers explicitly acknowledge data that was read and processed successfully. Readers are responsible for reading the chunks starting with the appropirate offsets. Data can expire after a set period of time if so desired (TODO). By default data does not expire at all.
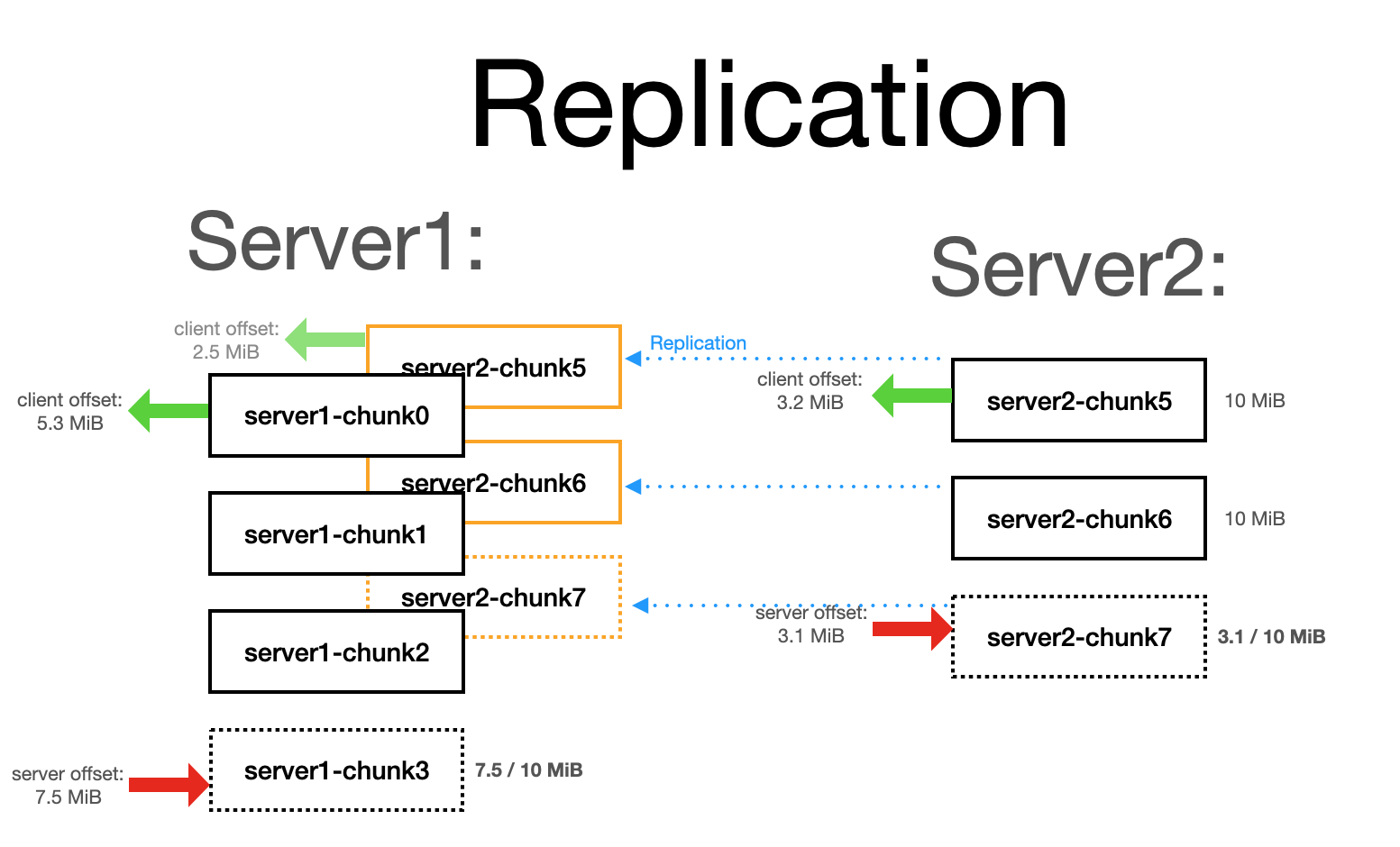
Replication
- Replication is asynchronous by default with an option to wait until the data written is replicated to at least N other servers.
- Every file in data directory looks like the following:
<category>/<server_name>-chunkXXXXXXXXX. - No leaders and followers: all chunks are replicated into all servers in the cluster, all nodes are equal (inspired by ClickHouse replication)
- Each instance in the cluster must have a unique name and it will be used as a prefix to all files in the category.
- Clients should only connect to a single instance and consume chunks written to all the servers because all data is replicated to every node.
- If a node permanently goes away the last chunk will be marked as complete after a (big) timeout.
Installation
- Install Go at https://golang.org/
- Run the following command in your terminal:
$ go install -v github.com/YuriyNasretdinov/chukcha@latest - The binary built should be located at
~/go/bin/chukchaor at$GOPATH/bin/chukchaif$GOPATHwas set.
Usage
It's too early to start using it yet! If you really want to, you can, of course, but keep in mind that this is a project still in the early days of it's development and it's API will probably change a lot before stabilising.
If you really want to use Chukcha, please refer to the simple Go client library at https://pkg.go.dev/github.com/YuriyNasretdinov/chukcha/client.
TODOs:
- Limit for the maximum message size is 1 MiB, otherwise we can no longer serve results from disk because we read from disk in 1 MiB chunks.
- Handle situations when we run out of disk space or the number of inodes.
- Compute code coverage.
- Introduce replication.
- Write replication tests
- Rotate chunks not only based on the size but also based on time passed, to allow chunks downloaded from other servers to be forcefully finalised upon failure.

