Baker
![]()
Baker is a high performance, composable and extendable data-processing pipeline for the big data era. It shines at converting, processing, extracting or storing records (structured data), applying whatever transformation between input and output through easy-to-write filters.
Baker is fully parallel and maximizes usage of both CPU-bound and I/O bound pipelines.
- Baker
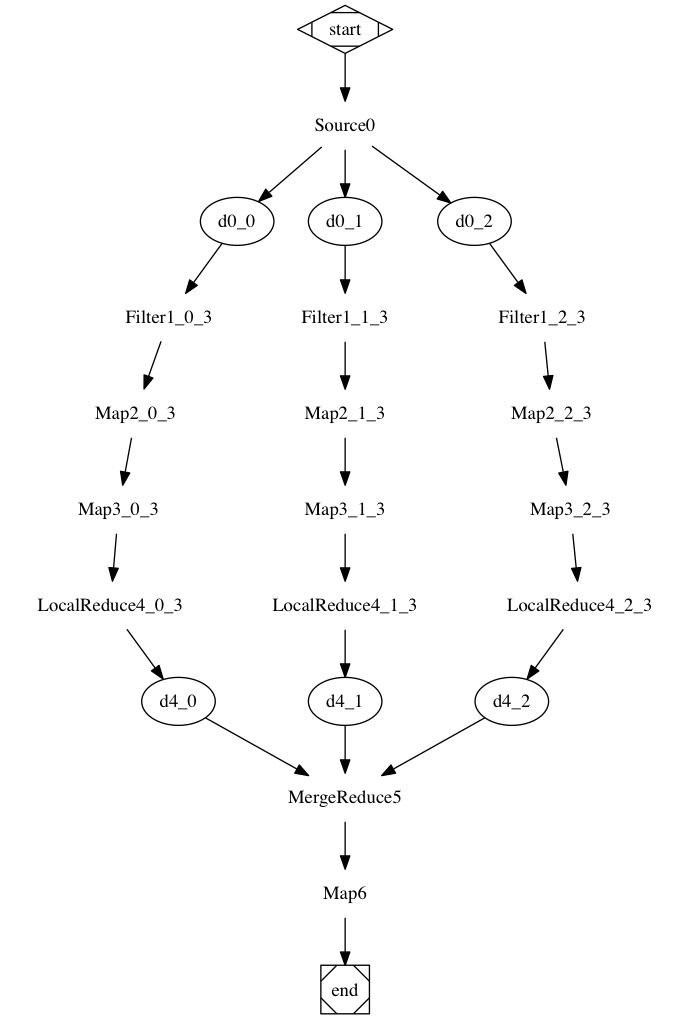
Pipelines
A pipeline is the configured set of operations that Baker performs during its execution.
It is defined by:
- One input component, defining where to fetch records from
- Zero or more filters, which are functions that can process records (reading/writing fields, clearing them or even splitting them into multiple records)
- One output component, defining where to send the filtered records to (and which columns)
- One optional upload component, defining where to send files produced by the output component (if any)
Notice that there are two main usage scenarios for Baker:
- Baker as a batch processor. In this case, Baker will go through all the records that are fed by the input component, process them as quickly as possible, and exit.
- Baker as a daemon. In this case, Baker will never exit; it will keep waiting for incoming records from the input component (e.g.: Kinesis), process them and send them to the output.
Selecting between scenario 1 or scenario 2 is just a matter of configuring the pipeline; in fact, it is the input component that drives the scenario. If the input component exits at some point, Baker will flush the pipeline and exit as well; if instead the input component is endless, Baker will never exit and thus behave like a daemon.
Usage
Baker uses a baker.Config struct to know what to do. The configuration can be created parsing a toml file with baker.NewConfigFromToml(). This function requires a baker.Components object including all available/required components.
This is an example of this struct:
comp := baker.Components{
Inputs: input.AllInputs(),
Filters: MyCustomFilters(),
// merge available outputs with user custom outputs
Outputs: append(output.AllOutputs(), MyCustomOutputs()...),
Uploads: MyCustomUploads(),
// optional: custom extra config
User: MyCustomConfigs(),
// optional: used if sharding is enabled
ShardingFuncs: MyRecordShardingFuncs,
// optional: used if records must be validated. Not used if [general.dont_validate_fields] is used in TOML
Validate: MyRecordValidationFunc,
// optional: functions to get fields indexes by name and vice-versa
FieldByName: MyFieldByNameFunc,
FieldNames: []string{"field0", "field1", "field2"},
}
Components (inputs, filters, outputs and uploads) are either generic ones provided with Baker or user-defined components, or a mix of both.
Performance
Read from S3 and write to local disk
On a c5.2xlarge instance, Baker managed to read zstandard records from S3, uncompress them and apply a basic filtering logic, compressing them back on local files with zstandard at compression level 3 and long range mode at 27 using ~90% of capacity of each vCPU (8 in total) and ~3.5GB of RAM.
It read and wrote a total of 94 million records in 8'51" (~178k r/w records per second).
On a c5.12xlarge instance (48vCPUs) the same test took 2'2" (~775k r/w records per second).
For this test we used 711 zstd compressed files for a total of 17 GB of compressed size and 374 GB of uncompressed size. The average size of each record was ~4.5 KB.
Read from S3 and write to DynamoDB (in the same region)
On a c5.4xlarge instance, Baker read zstd compressed files from S3 writing to DynamoDB (configured with 20k write capacity units) at an average speed of 60k records/s (the average size of each record is 4.3 KB) using less than 1 GB of memory and ~300% of the total CPU capacity (less than 20% for each core). The bottleneck here was the DynamoDB write capacity, so Baker can easily cope with an increased load just increasing the write capacity units in DynamoDB (up to 400k).
Read from Kinesis and write to DynamoDB (in the same region)
On a c5.4xlarge instance, we performed a test reading from a Kinesis stream with 130 shards and writing to a DynamoDB table with 20k write capacity units. Baker was able to read and write more than 10k records per second (the avg size of each record was 4.5 KB) using less than 1 GB of RAM and ~400% of the total CPU capacity (less than 25% for each core).
Baker and AWS Kinesis Data Firehose
On many aspects Baker can be compared with Firehose and so we did when we used Baker in one of the NextRoll project.
As mentioned in the NextRoll Tech Blog the price of that service, OMFG, if served using Amazon Firehose, would have been around $30k/month (not including S3 and data transfer costs). That monthly cost is more than the whole yearly cost of the service using Baker.
How to build a Baker executable
The examples/ folder contains several main() examples:
- basic: a simple example with minimal support
- filtering: shows how to code your own filter
- sharding: shows how to use an output that supports sharding (see below for details about sharding)
- help: shows components' help messages
- metrics: shows how to implement and plug a new metrics client to Baker
- advanced: an advanced example with most of the features supported by Baker
TOML Configuration files
This is a minimalist Baker pipeline TOML configuration that reads a record from the disk, updates its timestamp field with a "Timestamp" filter and pushes it to DynamoDB:
[input]
name="List"
[input.config]
files=["records.csv.gz"]
[[filter]]
name="ClauseFilter"
[output]
name="DynamoDB"
fields=["source","timestamp","user"]
[output.config]
regions=["us-west-2","us-east-1"]
table="TestTableName"
columns=["s:Source", "n:Timestamp", "s:User"]
[input] selects the input component, or where to read the records from. In this case, the List component is selected, which is a component that fetches CSV files from a list of local or remote paths/URLs. [input.config] is where component-specific configurations can be specified, and in this case we simply provide the files option to List. Notice that List would accept http:// or even s3:// URLs there in addition to local paths, and some more (run ./baker-bin -help List in the help example for more details).
[[filter]] In TOML syntax, the double brackets indicates an array of sections. This is where you declare the list of filters (i.e filter chain) to sequentially apply to your records. As other components, each filter may be followed by a [filter.config] section. This is an example:
[[filter]]
name="filterA"
[filter.config]
foo = "bar"
[[filter]]
name="filterB"
[output] selects the output component; the output is where records that made it to the end of the filter chain without being discarded end up. In this case, the DynamoDB output is selected, and its configuration is specified in [output.config].
The fields option in the [output] section selects which fields of the record will be send to the output. In fact, most pipelines don't want to send the full records to the output, but they will select a few important columns out of the many available columns. Notice that this is just a selection: it is up to the output component to decide how to physically serialize those columns. For instance, the DynamoDB component requires the user to specify an option called columns that specifies the name and the type of the column where the fields will be written.
Baker supports environment variables replacement in the configuration file. Use ${ENV_VAR_NAME} or $ENV_VAR_NAME and the value in the file will be replaced at runtime. Note that if the variable doesn't exist, then an empty string will be used for replacement.
How to create components
To register a new component within Baker and make it available for your pipelines, you must create and fill a description structure and provide it to baker.Components. The structure to fill up is either a InputDesc, FilterDesc, OutputDesc, UploadDesc or MetricsDesc, depending on the component type.
At runtime, components configurations (i.e [input.config], [output.config] and so on) are serialized from TOML and each of them forwarded to the component constructor function.
Configuration fields may contains some struct tags. Let's see their use with an example:
type MyConfig struct {
Name string `help:"Name is ..." required:"true"`
Value int `help:"Value is ..."`
Strings []string `help:"Strings ..." default:"[a, b, c]"`
}
Supported struct tags:
help: shown on the terminal when requesting this component's helpdefault: also shown in the component helprequired: also shown in help. Configuration fails if the field is not set in TOML (or let to itds zero value).
Filters
An example code can be found at ./examples/filtering/filter.go
A filter must implement a baker.Filter interface:
type Filter interface {
Process(r Record, next func(Record))
Stats() FilterStats
}
While Stats() returns a struct used to collect metrics (see the Metrics chapter), the Process() function is where the filter logic is actually implemented.
Filters receive a Record and the next() function, that represents the next filtering function in the filter chain.
The filter can do whatever it likes with the Record, like adding or changing a value, dropping it (not calling the next() function) or even splitting a Record calling next() multiple times.
baker.FilterDesc
In case you plan to use a TOML configuration to build the Baker topology, the filter should also be described using a baker.FilterDesc struct. In fact a list of baker.FilterDesc will be used to populate baker.Components, which is an argument of baker.NewConfigFromToml.
type FilterDesc struct {
Name string
New func(FilterParams) (Filter, error)
Config interface{}
Help string
}
Name
The Name of the filter must be unique as it will match the toml [filter] configuration:
[[filter]]
name = "FilterName"
[filter.config]
filterConfKey1 = "somevalue"
filterConfKey2 = "someothervalue"
New
This is the constructor and returns the baker.Filter interface as well as a possible error.
Config
The filter can have its own configuration (as the [filter.config] fields above). The Config field will be populated with a pointer to the configuration struct provided.
The New function will receive a baker.FilterParams. Its DecodedConfig will host the filter configuration. It requires a type assertion to the filter configuration struct type to be used:
func NewMyCustomFilter(cfg baker.FilterParams) (baker.Filter, error) {
if cfg.DecodedConfig == nil {
cfg.DecodedConfig = &MyCustomFilterConfig{}
}
dcfg := cfg.DecodedConfig.(*MyCustomFilterConfig)
}
Help
The help string can be used to build an help output (see the help example).
Inputs
An input is described to baker by filling up a baker.InputDesc struct.
The New function must return a baker.Input component whose Run function represents the hearth of the input.
That function receives a channel where the data produced by the input must be pushed in form of a baker.Data.
The actual input data is a slice of bytes that will be parsed with Record.Parse() by Baker before sending it to the filter chain. The input can also add metadata to baker.Data. Metadata can be user-defined and filters must know how to read and use metadata defined by the input.
Outputs
An output must implement the Output interface:
type Output interface {
Run(in <-chan OutputRecord, upch chan<- string)
Stats() OutputStats
CanShard() bool
}
The nop output is a simple implementation of an output and can be used as source.
The fields configuration of the output (like fields=["field", "field", ...]) tells which record fields will populate the OutputRecord.Fields slice that is sent to the output as its input. The values of the slice will have the same order as the fields configuration.
The procs setting in the [output] TOML defines how many instances of the output are going to be created (i.e the New constructor function is going to be called procs times).
Each instance receives its index over the total in OutputParams.Index, which is passed to the output New function.
Which output instance a record is sent to, depends on the sharding function (see the sharding section).
NOTE: If procs>1 but sharding is not set up, procs is set back to 1.
Sharding (which is explained below) is strictly connected to the output component but it's also transparent to it. An output will never know how the sharding is calculated, but records with the same value on the field used to calculate sharding will be always sent to the output process with the same index (unless a broken sharding function is used).
The output also receives an upload channel where it can send strings to the uploader. Those strings will likely be paths to something produced by the output (like files) that the uploader must upload somewhere.
Raw outputs
An output can declare itself as "raw". A raw output will receive, in addition to optional selected fields, also the whole serialized record as a []byte buffer.
Serializing a record has a cost, that's why each output must choose to receive it and the default is not to serialize the whole record.
Uploads
Outputs can, if applicable, send paths to local files to a chan string. Uploads read from this channel and can do whatever they desire with those path. As an example upload.S3 uploads them to S3..
The uploader component is optional, if missing the string channel is simply ignored by Baker.
How to create a '-help' command line option
The ./examples/help/ folder contains a working example of command that shows a generic help/usage message and also specific component help messages when used with -help
Provided Baker components
Inputs
KCL
input.KCL fetches records from AWS Kinesis using vmware-go-kcl, an implementation of the KCL (Kinesis Client Library). KCL provides a way to to process a single Kinesis stream from multiple Baker instances, each instance consuming a number of shards.
The KCL takes care of balancing the shards between workers. At the time of writing, vmware-go-kcl doesn't implement shard stealing yet, so it's advised to set MaxShards to a reasonable value. Since the number of shards doesn't change often, dividing the number of total shards by the expected number of baker instances and rounding up to the next integer has given us good results.
The association between shards and baker instances (or workers) are called leases. Lease synchronization is taken care of by KCL; to do so it requires access to a DynamoDB table, which named depends on the configured AppName.
Leases are updated at regular interval defined by ShardSync.
The dynamodb table also serves the purpose of checkpointing, that is keeping track of the per-shard advancement by writing the ID last read record (checkpoint).
InitialPosition defines the initial checkpoint position for consuming new shards. This parameter is only effective the first time a shard ID is encountered, since after that the lease will associate the shard and a record checkpoint. It can either be set to LATEST or TRIM_HORIZON.
Note that when new shards are created in the event of a resharding, KCL may not immediately be aware of their creation. Setting TRIM_HORIZON is thus a safer choice here since eventually all the records from the newly created shards will be consumed, as opposed to LATEST, which can lead to some missing records.
Implementation and throttling prevention
Within a Baker instance, the KCL input creates as many record processors as there are shards to read from. A record processor pulls records by way of the GetRecords AWS Kinesis API call.
AWS imposes limits on GetRecords, each shard can support up to a maximum total data read rate of 2 MiB per second via GetRecords. If a call to GetRecords returns 10 MiB, the maximum size GetRecords is allowed to return, subsequent calls made within the next 5 seconds will meet a ProvisionedThroughputExceededException. Limiting the number of records per call would work but would increase the number of performed IO syscalls and will increase the risk to meet the limits imposed by AWS on API calls or to not process records as fast as possible.
The strategy we're using is to not limit MaxRecords but sleeping for 6s. Doing so, we're guaranteed to never exceed the per-shard read througput limit of 2MB/s, while being close to it on data peaks. This has the added advantage of reducing the number of IO syscalls.
Working with baker.Record
baker.Record is an interface which provides an abstraction over a record of flattened data, where columns of fields are indexed through integers.
At the moment, baker proposes an unique Record implementation, baker.LogLine.
baker.LogLine CSV record
baker.LogLine is an highly optimized CSV compatible Record implementation. It supports any single-byte field separator and doesn't handle quotes (neither single nor double). The maximum number of fields is hard-coded by the LogLineNumFields constant which is 3000. 100 extra fields can be stored at runtime in a LogLine (also hardcoded with NumFieldsBaker), these extra fields are a fast way to exchange data between filters and/or outputs but they are neither handled during Parsing (i.e LogLine.Parse) nor serialization (LogLine.ToText).
If the hardcoded values for LogLineNumFields and NumFieldsBaker do not suit your needs, it's advised that you copy logline.go in your project and modify the constants declared at the top of the file. Your specialized LogLine will still implement baker.Record and thus can be used in lieu of baker.LogLine. To do so, you need to provide a CreateRecord function to baker.Components when calling baker.NewConfigFromToml.
For example:
comp := baker.Components{}
comp.CreateRecord = func() baker.Record {
return &LogLine{FieldSeparator:','}
}
Tuning parallelism
When testing Baker in staging environment, you may want to experiment with parallelism options to try and obtain the best performance. Keep an eye on htop as the pipeline runs: if CPUs aren't saturated, it means that Baker is running I/O-bound, so depending on the input/output configuration you may want to increase the parallelism and squeeze out more performance.
These are the options you can tune:
- Section
[filterchain]:procs: number of parallel goroutines running the filter chain (default: 16)
- Section
[output]:procs: number of parallel goroutines sending data to the output (default: 32)
Sharding
Baker supports sharding of output data, depending on the value of specific fields in each record. Sharding makes sense only for some specific output components, so check out their documentation. A component that supports sharding must return true from the function CanShard().
To configure sharding, it's sufficient to create a sharding key in [output] section, specifying the column on which the sharding must be executed. For a field to be shardable, a ShardingFunc must exist for that field (see baker.Components.ShardingFuncs).
Since the sharding functions provide the capability to spread the records across different output procs (parallel goroutines), it's clear that the [output] configuration must include a procs value greater than 1 (or must avoid including it as the default value is 32).
How to implement a sharding function
The ./examples/sharding/ folder contains a working example of an output that supports sharding and a main() configuration to use it together with simple sharding functions.
Stats
While running, Baker dumps stats on stdout every second. This is an example line:
Stats: 1s[w:29425 r:29638] total[w:411300 r:454498] speed[w:27420 r:30299] errors[p:0 i:0 f:0 o:0 u:0]
The first bracket shows the number of records that were read (i.e. entered the pipeline) and written (i.e. successfully exited the pipeline) in the last 1-second window. The second bracket is total since the process was launched (the u: key is the number of files successfully uploaded). The third bracket shows the average read/write speed (records per second).
The fourth bracket shows the records that were discarded at some point during the records because of errors:
p:is the number of records that were discarded for a parsing errori:is the number of records that were discarded because an error occurred within the input component. Most of the time, this refers to validation issues.f:is the number of records that were discarded by the filters in the pipeline. Each filter can potentially discard records, and if that happens, it will be reported here.o:is the number of records that were discarded because of an error in the output component. Notice that output components should be resilient to transient network failures, and they abort the process in case of permanent configuration errors, so the number here reflects records that could not be permanently written because eg. validation issues. Eg. think of an output that expects a column to be in a specific format, and rejects records where that field is not in the expected format. A real-world example is empty columns that are not accepted by DynamoDB.u:is the number records whose upload has failed
Metrics
During execution, Baker gathers some general metrics from the components present in the topology. More specific metrics can also be generated by components.
Metrics are then exported via an implementation of the baker.MetricsClient interface. At the moment, the only implementation is datadog.Client.
Configuration of the metrics client happens in the baker TOML configuration file:
[metrics]
name="datadog"
[metrics.config]
host="localhost:8125" # host of the dogstatsd client to which send metrics to (in UDP)
prefix="myapp.baker." # prefix to prepend to the name of all exported metrics
send_logs=true # whether log messages should be sent (as Dogstatd) events
tags=["tag1:foo", "tag2:bar"] # tags to associate to all exported metrics
The fields available in the [metrics.config] section depends on the metrics.Client implementation, chosen with name value in the [metrics] parent section.
The metrics examples shows an example implementation of baker.MetricsClient and how to plug it to Baker so that it can be chosen in the [metrics] TOML section and used to export Baker metrics.
Aborting (CTRL+C)
By design, Baker attempts a clean shutdown on CTRL+C (SIGINT). This means that it will try to flush all records that it's currently processing and correctly flush/close any output.
Depending on the configured pipeline and the requested parallelism, this could take anything from a few seconds to a minute or so (modulo bugs...). Notice that improving this requires active development, so feel free to open an issue if it's not working fast enough fo you.
If you need to abort right away, you can use CTRL+\ (SIGQUIT).
Baker test suite
Run baker test suite with: go test -v -race ./...
The code also includes several benchmarks.
Package structure
./pkg contains reusable packages providing various utilities that are not specifically Baker-related, though of course they may come handy while developping new baker components.