Design
This is a very perlimenary PR for the query module so far. Much things have to be considered further.
Since it would be a principle module, I just want to discuss the current design/implementation ASAP to avoid improper design and find some better ideas to proceed.
Logical Plan
A Logical Plan is a DAG (Directed Acyclic Graph) of Params.
The Param defines necessary parameters for query execution. The parameters are well prepared during the logical plan composing in order to reduce extra cost while executing physical plan.
Plot
the logical plan can be plotted as Dot graph. For example,
digraph {
n2[label="ChunkIDsFetch{metadata={group=skywalking,name=trace},projection=[TraceID startTime]}"];
n1[label="ChunkIDsMerge{}"];
n7[label="IndexScan{begin=1623203253604099000,end=1623214053604099000,KeyName=duration,conditions=[<=1000],metadata={group=skywalking,name=trace}}"];
n4[label="Pagination{Offset=0,Limit=0}"];
n5[label="Root{}"];
n3[label="SortMerge{fieldName=startTime,sort=DESC}"];
n6[label="TraceIDFetch{TraceID=aaaaaaaa,metadata={group=skywalking,name=trace},projection=[TraceID startTime]}"];
n2->n3;
n1->n2;
n7->n1;
n5->n6;
n5->n7;
n3->n4;
n6->n3;
}
We can leverage the online toolkit to visualize the logical plan,
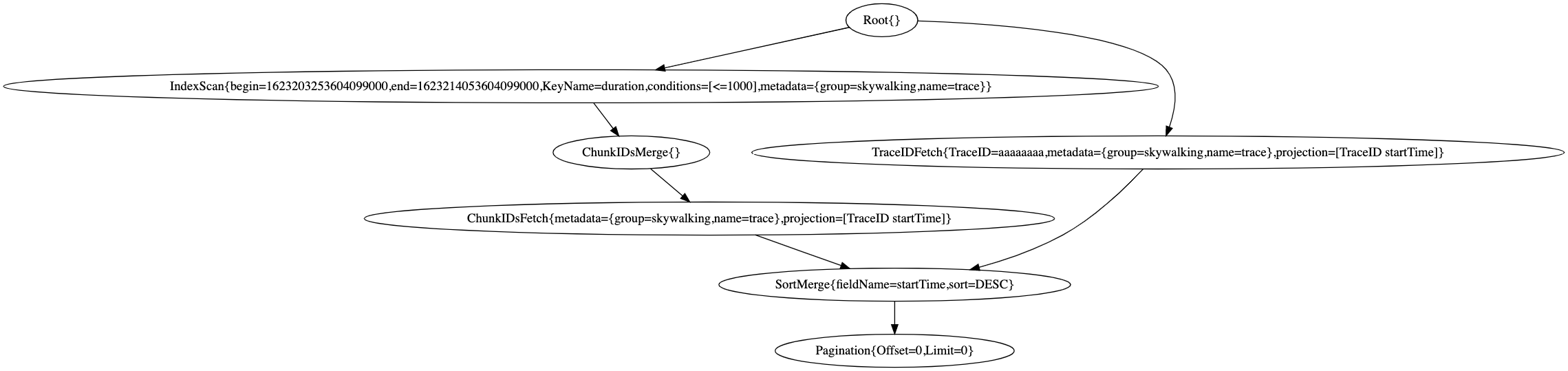
Physical Plan
A Physical Plan contains the logical plan and the Transform(s) corresponding to each logical.Op.
While the plan is triggered to run, a reversed topology-sorted slices (Future as items) will be generated from the logical plan.
Tasks
- [x] client utils for building
EntityCriteria
- [x] logical plan: Ops such as Sort, OffsetAndLimit, ChunkIDMerge, TableScan and IndexScan
- [x] physical plan: topology sort,
Transform
- [ ] complete API to connect with
Liaison (Add handlers) (Maybe next PR)
To be discussed
Index selection and optimization stage
For now, I only use single-value indexes. But in the current implementation, we may be able to improve index selection during the process of generating Logical Plan.
Any better idea? Since for the traditional databases, normally they have optimization stages (usually after generating hierarchical logical plan?) for indexes selection. How can we fit this optimization stage in our implementations?
Sort and field orderliness
I believe we have to impose stronger preconditions to sort-field since it is not possible to sort on a sparse field.
And Sort requires the Field to be arranged in a strict order, i.e. we have to use fieldIndex number to access the field that is needed to be sorted quickly. Otherwise, it may cost much resources to find the specific field every time.




 Sliding windows can fulfill our requirement in the sense that we need to flush the data more frequently.
Sliding windows can fulfill our requirement in the sense that we need to flush the data more frequently.




 It provides add, delete, edit and batch delete functions too.
It provides add, delete, edit and batch delete functions too.