Churro - ETL for Kubernetes
churro is a cloud-native Extract-Transform-Load (ETL) application designed to build, scale, and manage data pipeline applications.
What is churro?
churro is an application that processes input files and streams by extracting content and loading that content into a database of your choice, all running on Kubernetes. Today, churro supports processing of JSON, XML, XLSX, CSV files along with JSON API streams. End users create churro pipelines to process data, those pipelines can be created using the churro web app or via a churro pipeline custom resource (yaml) directly.
Design
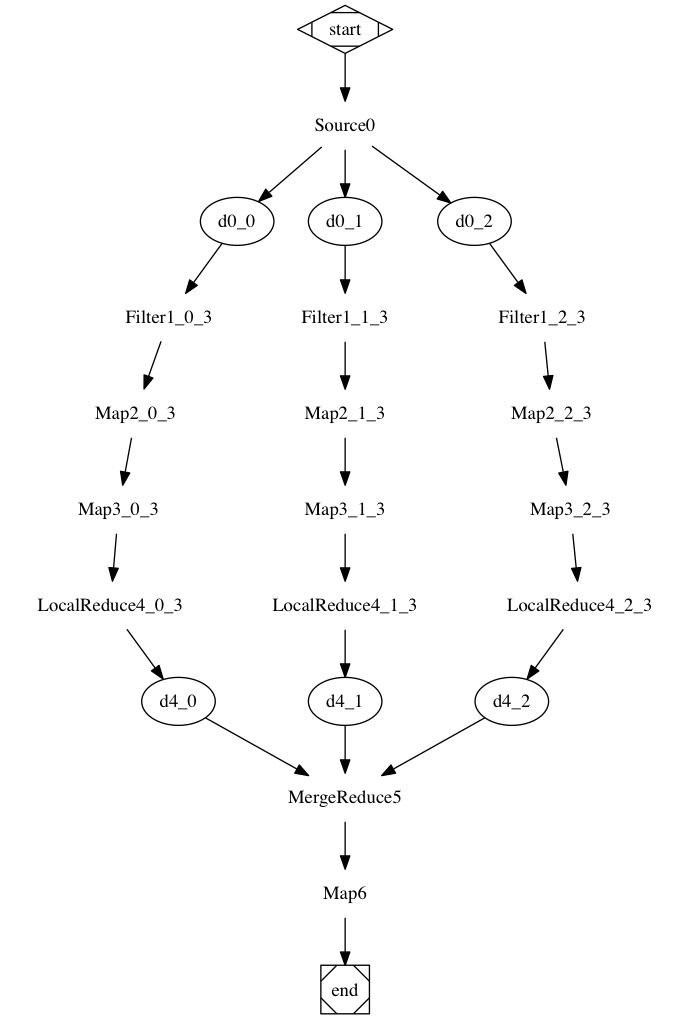
Some key aspects of the churro design:
- churro is designed from the start to run within a Kubernetes cluster.
- churro uses a micro-service architecture to scale ETL processing
- churro has extension points defined to allow for customized processing to be performed per customer requirements.
- churro is written in golang
- churro currently supports persisting ingested data into cockroachdb, singlestore, and mysql databases
- churro implements a kubernetes operator to handle git-ops style provisioning of churro pipeline resources including the pipeline database
For more details on the churro design, checkout out the documentation at the churro github pages.
Docs
Detailed documentation is found at the churro github pages, additional content such as blogs can be found at the churrodata.com web site.
Images
Today, churro container images are found on DockerHub here. These images are muulti-arch manifest images that include builds for both amd64 and arm64 architectures.
churro Cloud
Inquires about churro Cloud can be directed to [email protected]. In the near future, users will be able to provision a churro instance on the cloud of their choice, with billing and management handled by churrodata.com
Starting with churro
People generally start with churro by creating a kubernetes cluster, then deploying churro to your running cluster. Installation documentation is found on the churro github pages.
Contributing
Since churro is open source, you can view the source code and make contributions such as pull requests on our github.com site. We encourage users to log any issues they find on our github issues site.
Support
churro enterprise support and services are provided by churrodata.com.