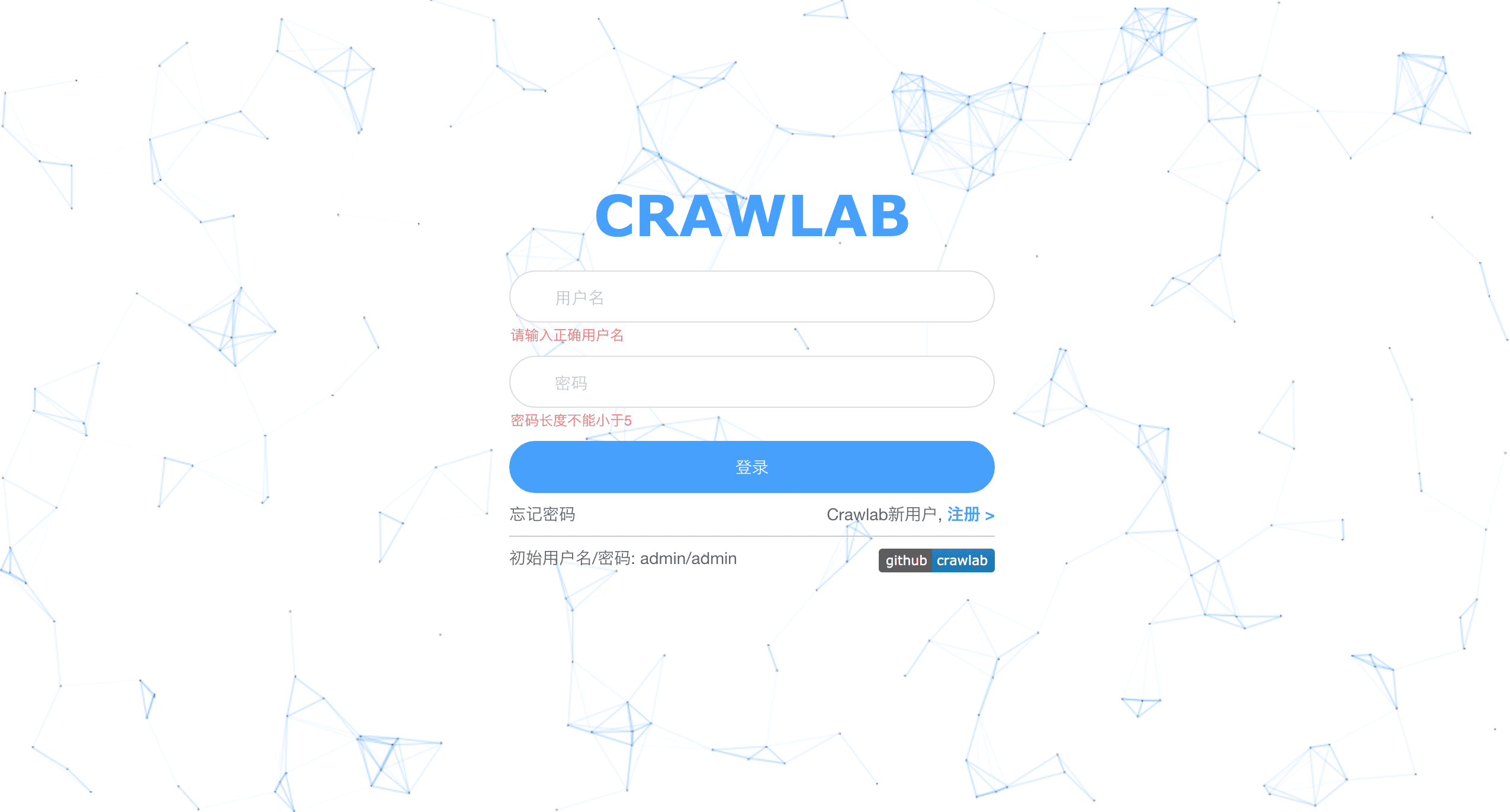
page-fetch
page-fetch is a tool for researchers that lets you:
- Fetch web pages using headless Chrome, storing all fetched resources including JavaScript files
- Run arbitrary JavaScript on many web pages and see the returned values
Installation
page-fetch is written with Go and can be installed with go get:
▶ go get github.com/detectify/page-fetch
Or you can clone the respository and build it manually:
▶ git clone https://github.com/detectify/page-fetch.git
▶ cd page-fetch
▶ go install
Dependencies
page-fetch uses chromedp, which requires that a Chrome or Chromium browser be installed. It uses the following list of executable names in attempting to execute a browser:
headless_shellheadless-shellchromiumchromium-browsergoogle-chromegoogle-chrome-stablegoogle-chrome-betagoogle-chrome-unstable/usr/bin/google-chrome
Basic Usage
page-fetch takes a list of URLs as its input on stdin. You can provide the input list using IO redirection:
▶ page-fetch < urls.txt
Or using the output of another command:
▶ grep admin urls.txt | page-fetch
By default, responses are stored in a directory called 'out', which is created if it does not exist:
▶ echo https://detectify.com | page-fetch
GET https://detectify.com/ 200 text/html; charset=utf-8
GET https://detectify.com/site/themes/detectify/css/detectify.css?v=1621498751 200 text/css
GET https://detectify.com/site/themes/detectify/img/detectify_logo_black.svg 200 image/svg+xml
GET https://fonts.googleapis.com/css?family=Merriweather:300i 200 text/css; charset=utf-8
...
▶ tree out
out
├── detectify.com
│ ├── index
│ ├── index.meta
│ └── site
│ └── themes
│ └── detectify
│ ├── css
│ │ ├── detectify.css
│ │ └── detectify.css.meta
...
The directory structure used in the output directory mirrors the directory structure used on the target websites. A ".meta" file is stored for each request that contains the originally requested URL, including the query string), the request and response headers etc.
Options
You can get the page-fetch help output by running page-fetch -h:
▶ page-fetch -h
Request URLs using headless Chrome, storing the results
Usage:
page-fetch [options] < urls.txt
Options:
-c, --concurrency Concurrency Level (default 2)
-e, --exclude Do not save responses matching the provided string (can be specified multiple times)
-i, --include Only save requests matching the provided string (can be specified multiple times)
-j, --javascript JavaScript to run on each page
-o, --output Output directory name (default 'out')
-w, --overwrite Overwrite output files when they already exist
--no-third-party Do not save responses to requests on third-party domains
--third-party Only save responses to requests on third-party domains
Concurrency
You can change how many headless Chrome processes are used with the -c / --concurrency option. The default value is 2.
Excluding responses based on content-type
You can choose to not save responses that match particular content types with the -e / --exclude option. Any response with a content-type that partially matches the provided value will not be stored; so you can, for example, avoid storing image files by specifying:
▶ page-fetch --exclude image/
The option can be specified multiple times to exclude multiple different content-types.
Including responses based on content-type
Rather than excluding specific content-types, you can opt to only save certain content-types with the -i / --include option:
▶ page-fetch --include text/html
The option can be specified multiple times to include multiple different content-types.
Running JavaScript on each page
You can run arbitrary JavaScript on each page with the -j / --javascript option. The return value of the JavaScript is converted to a string and printed on a line prefixed with "JS":
▶ echo https://example.com | page-fetch --javascript document.domain
GET https://example.com/ 200 text/html; charset=utf-8
JS (https://example.com): example.com
This option can be used for a very wide variety of purposes. As an example, you could extract the href attribute from all links on a webpage:
▶ echo https://example.com | page-fetch --javascript '[...document.querySelectorAll("a")].map(n => n.href)' | grep ^JS
JS (https://example.com): [https://www.iana.org/domains/example]
Setting the output directory name
By default, files are stored in a directory called out. This can be changed with the -o / --output option:
▶ echo https://example.com | page-fetch --output example
GET https://example.com/ 200 text/html; charset=utf-8
▶ find example/ -type f
example/example.com/index
example/example.com/index.meta
The directory is created if it does not already exist.
Overwriting files
By default, when a file already exists, a new file is created with a numeric suffix, e.g. if index already exists, index.1 will be created. This behaviour can be overridden with the -w / --overwrite option. When the option is used matching files will be overwritten instead.
Excluding third-party responses
You may sometimes wish to exclude responses from third-party domains. This can be done with the --no-third-party option. Any responses to requests for domains that do not match the input URL, or one of its subdomains, will not be saved.
Including only third-party responses
On rare occasions you may wish to only store responses to third party domains. This can be done with the --third-party option.