![]()
GraphJin - Build APIs in 5 minutes

GraphJin gives you a high performance GraphQL API without you having to write any code. GraphQL is automagically compiled into an efficient SQL query. Use it either as a library or a standalone service.
Sponsors
GraphJin is an Apache-licensed open source project with its ongoing development made possible entirely by the support of these awesome backers. If you'd like to join them, please consider:

1. Quick Install
Mac (Homebrew)
brew install dosco/graphjin/graphjin
Ubuntu (Snap)
sudo snap install --classic graphjin
Debian and Redhat (releases)
Download the .deb or .rpm from the releases page and install with dpkg -i and rpm -i respectively.
Go Install
go get github.com/dosco/graphjin
2. Create New API
graphjin new <app_name>
cd <app_name>
docker-compose run api db:setup
docker-compose up
About GraphJin
After working on several products through my career I found that we spend way too much time on building API backends. Most APIs also need constant updating, and this costs time and money.
It's always the same thing, figure out what the UI needs then build an endpoint for it. Most API code involves struggling with an ORM to query a database and mangle the data into a shape that the UI expects to see.
I didn't want to write this code anymore, I wanted the computer to do it. Enter GraphQL, to me it sounded great, but it still required me to write all the same database query code.
Having worked with compilers before I saw this as a compiler problem. Why not build a compiler that converts GraphQL to highly efficient SQL.
This compiler is what sits at the heart of GraphJin, with layers of useful functionality around it like authentication, remote joins, rails integration, database migrations, and everything else needed for you to build production-ready apps with it.
Better APIs Faster!
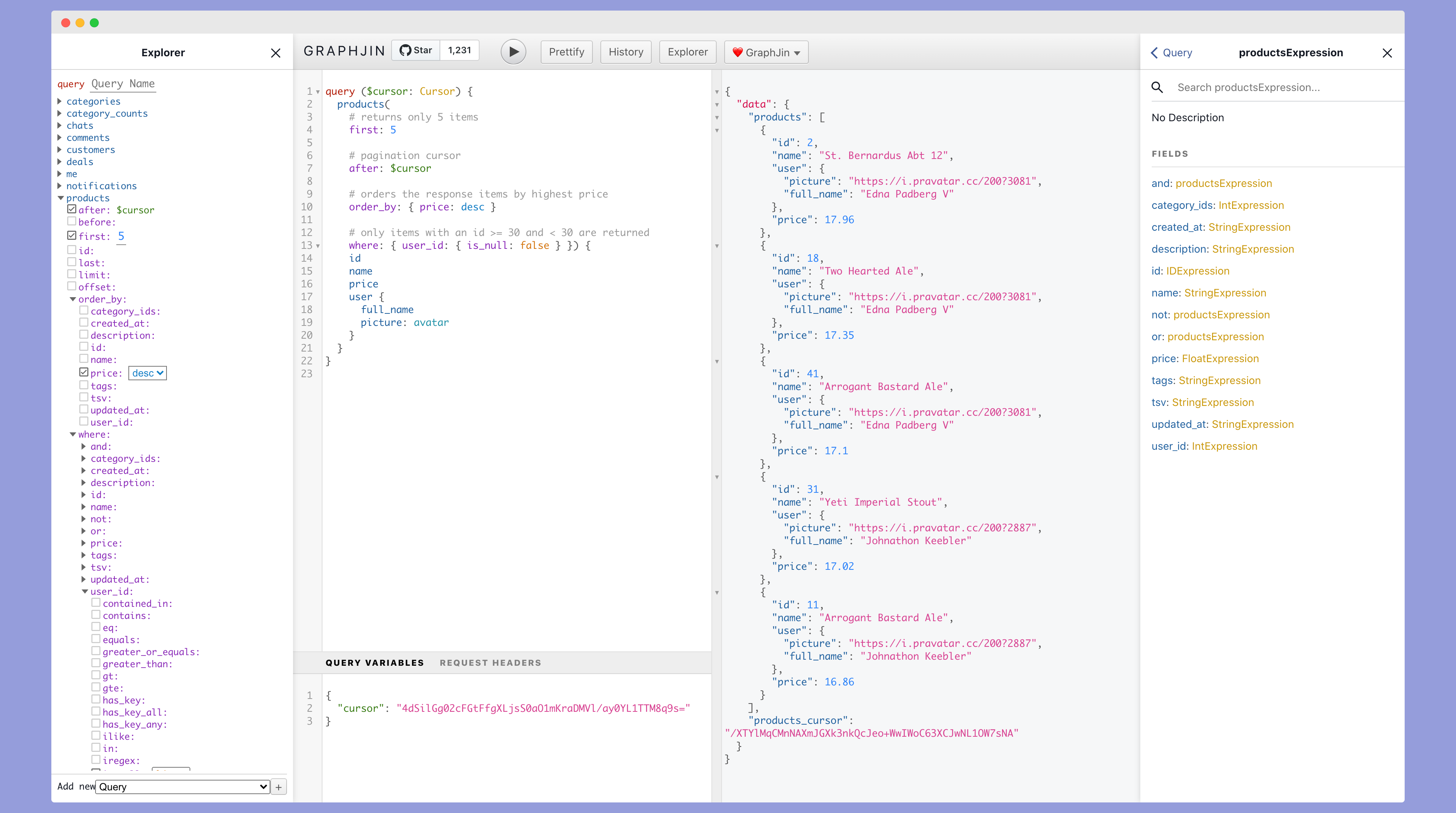
Lets take for example a simple blog app. You'll probably need the following APIs user management, posts, comments, votes. Each of these areas need apis for listing, creating, updating, deleting. Off the top of my head thats like 12 APIs if not more. This is just for managing things for rendering the blog posts, home page, profile page you probably need many more view apis that fetch a whole bunch of things at the same time. This is a lot and we're still talking something simple like a basic blogging app. All these APIs have to be coded up by someone and then the code maintained, updated, made secure, fast, etc. We are talking weeks to months of work if not more. Also remember your mobile and web developers have to wait around till this is all done.
With GraphJin your web and mobile developers can start building instantly. All they have to do is just build the GraphQL queries they need and GraphJin fetches the data. Nothing to maintain no backend API code, its secure, lighting fast and has tons of useful features like subscriptions, rate limiting, etc built-in. With GraphJin your building APIs in minutes not days.
Features
- Works with Postgres, MySQL8 and Yugabyte DB
- Complex nested queries and mutations
- Realtime updates with subscriptions
- Build infinite scroll, feeds, nested comments, etc
- Auto learns database tables and relationships
- Role and Attribute-based access control
- Opaque cursor-based efficient pagination
- Full-text search and aggregations
- JWT tokens supported (Auth0, JWKS, Firebase, etc)
- Join database queries with remote REST APIs
- Also works with existing Ruby-On-Rails apps
- Rails authentication supported (Redis, Memcache, Cookie)
- A simple config file
- High performance Go codebase
- Tiny docker image and low memory requirements
- Fuzz tested for security
- Database migrations tool
- Database seeding tool
- OpenCensus Support: Zipkin, Prometheus, X-Ray, Stackdriver
- API Rate Limiting
- Highly scalable and fast
Documentation
Build APIs in 5 minutes with GraphJin
Using it in your own code
go get github.com/dosco/graphjin/core
package main
import (
"context"
"database/sql"
"fmt"
"log"
"github.com/dosco/graphjin/core"
_ "github.com/jackc/pgx/v4/stdlib"
)
func main() {
db, err := sql.Open("pgx", "postgres://postgres:@localhost:5432/example_db")
if err != nil {
log.Fatal(err)
}
sg, err := core.NewGraphJin(nil, db)
if err != nil {
log.Fatal(err)
}
query := `
query {
posts {
id
title
}
}`
ctx := context.Background()
ctx = context.WithValue(ctx, core.UserIDKey, 1)
res, err := sg.GraphQL(ctx, query, nil)
if err != nil {
log.Fatal(err)
}
fmt.Println(string(res.Data))
}
Reach out
We're happy to help you leverage GraphJin reach out if you have questions
discord/graphjin (Chat)
Production use
The popular 42papers.com site for discovering trending papers in AI and Computer Science uses GraphJin for it's entire backend.
License
Copyright (c) 2019-present Vikram Rangnekar














