Dev Lake

![]()
| English | 中文 |
|---|
What is Dev Lake?
Dev Lake is the one-stop solution that integrates, analyzes, and visualizes software development data throughout the software development life cycle (SDLC) for engineering teams.
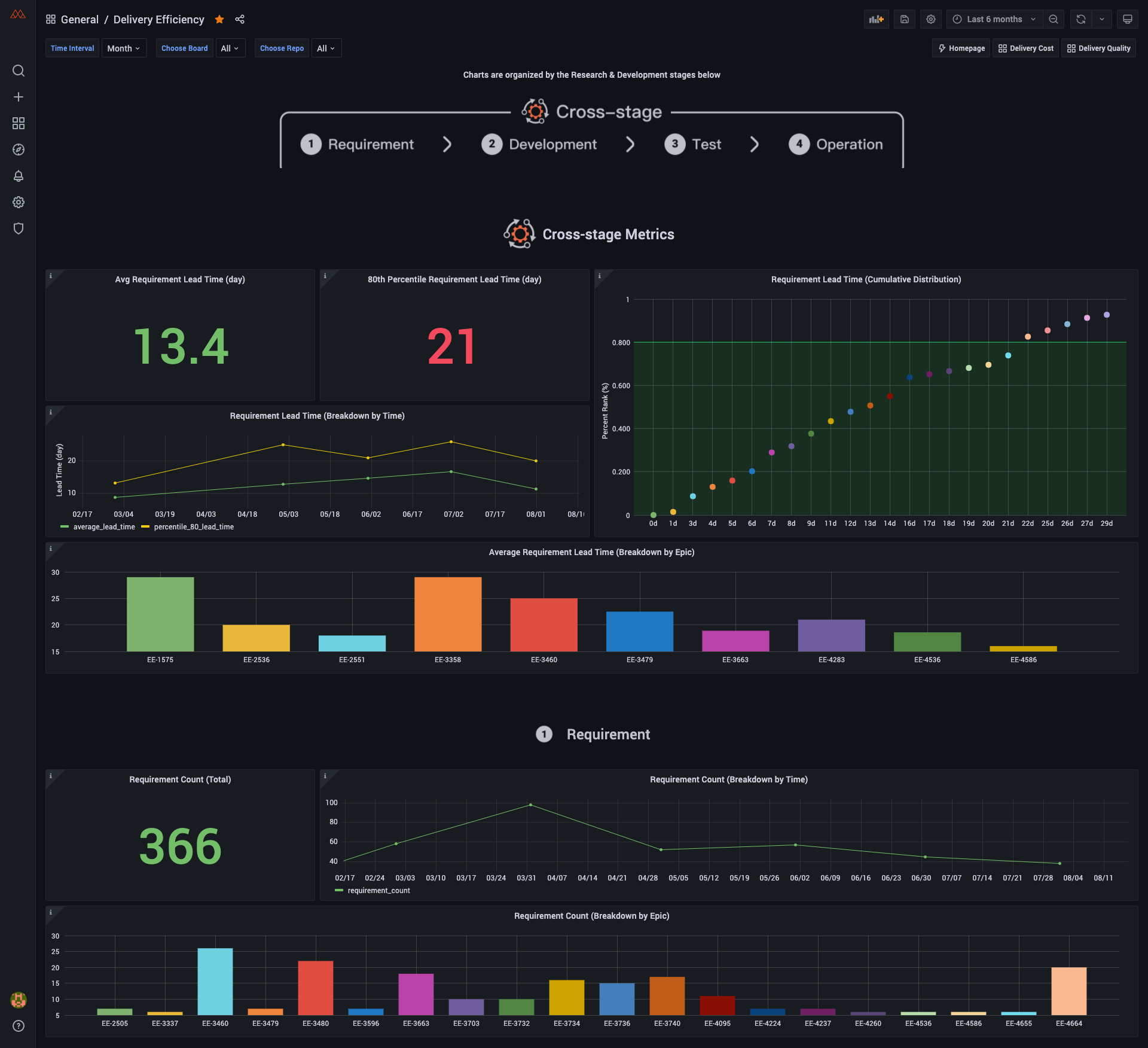
Dashboard Screenshot
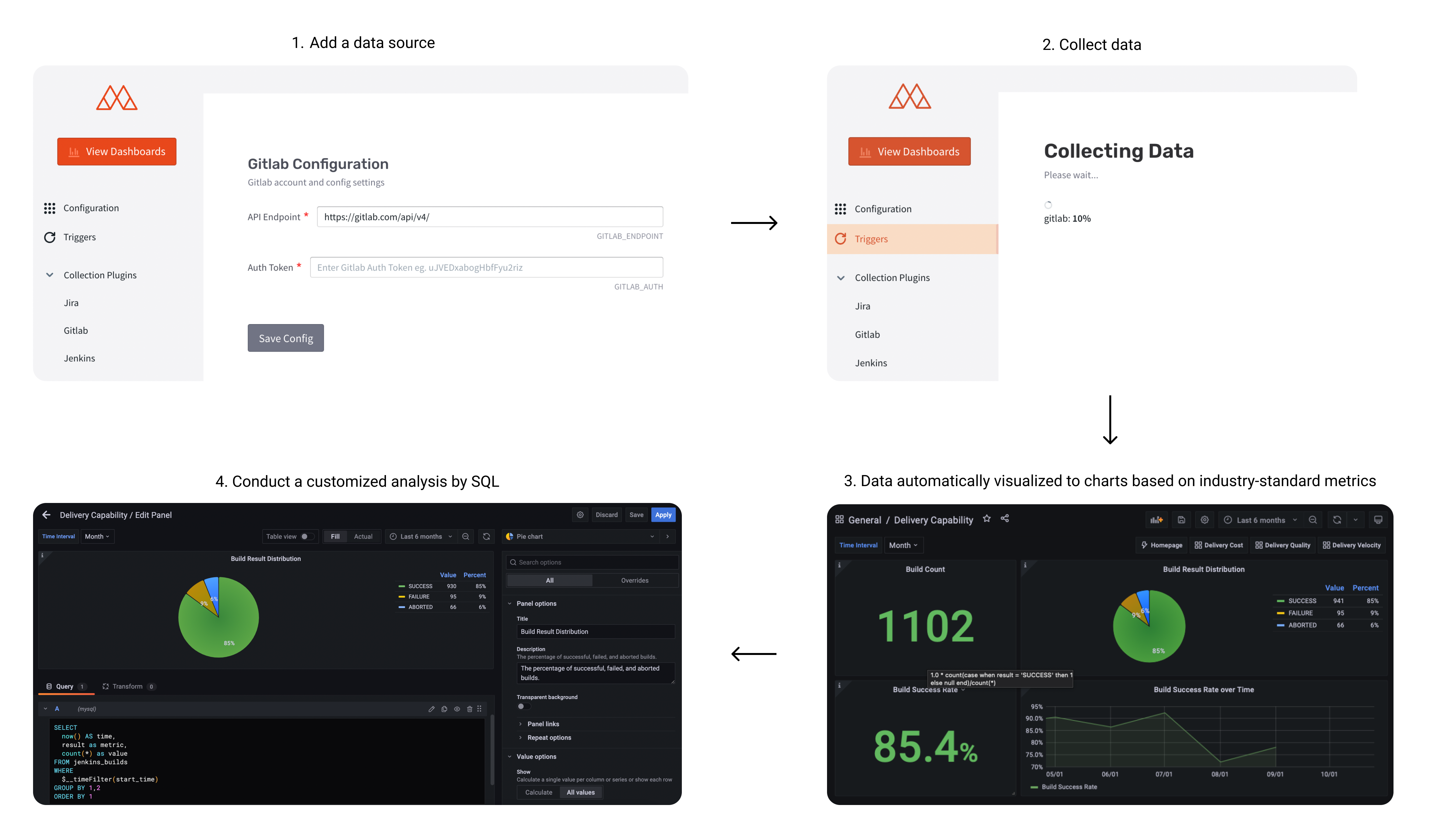
User Flow
Why Dev Lake?
- Unifies data from multiple sources (Jira, Gitlab, Jenkins etc) in one place.
- Can compute metrics from different data sources together.
- Provide a series of industry standard metrics to identify engineering problems.
- Highly customisable, users can make their own graphs, metrics & dashboards.
What can be accomplished with Dev Lake?
- Visualize and analyze your entire SDLC process in one personalized, unified view.
- Debug process- and team-level issues, scale successes.
- Unify and standardize measures of success and benchmarks.
Contents
| Section | Description | Documentation Link |
|---|---|---|
| Data Sources | Links to specific plugin usage & details | View Section |
| User Setup | Steps to run the project as a user | View Section |
| Developer Setup | How to setup dev environment | View Section |
| Tests | Commands for running tests | View Section |
| Grafana | How to visualize the data | View Section |
| Build a Plugin | Details on how to make your own | Link |
| Add Plugin Metrics | Guide to adding plugin metrics | Link |
| Contributing | How to contribute to this repo | Link |
| FAQ | Frequently Asked Questions | Link |
Data Sources We Currently Support
Below is a list of data source plugins used to collect & enrich data from specific sources. Each have a README.md file with basic setup, troubleshooting and metrics info.
For more information on building a new data source plugin see Build a Plugin.
| Section | Section Info | Docs |
|---|---|---|
| Jira | Metrics, Generating API Token, Find Board ID | Link |
| Gitlab | Metrics, Generating API Token, Find Project ID | Link |
| Jenkins | Metrics, Generating API Token | Link |
User setup
NOTE: If you only plan to run the product, this is the only section you should need NOTE: Commands written like this are to be run in your terminal
Required Packages to Install
NOTE: After installing docker, you may need to run the docker application and restart your terminal
Commands to run in your terminal
-
Clone repository
git clone https://github.com/merico-dev/lake.git devlake cd devlake cp .env.example .env -
Start Docker on your machine and then you can run
docker-compose up -d config-uito start up the configuration interfaceFor more info on how to configure plugins, please refer to the data source plugins section
-
Visit
localhost:4000to setup configuration files- Finish the configuration on the main configuration page (
localhost:4000) - Navigate to desired plugins pages on the sidebar under "Plugins", e.g. Jira, Gitlab, Jenkins etc. Enter in required information for those plugins
- Submit the form to update the values by clicking on the Save Config button on each form page
- Finish the configuration on the main configuration page (
-
Run
docker-compose up -dto start up the other services -
Visit
localhost:4000/triggersto trigger data collectionPlease replace your gitlab projectId and jira boardId in the request body. Click the Trigger Collection button. This can take up to 20 minutes for large projects. (gitlab 10k+ commits or jira 5k+ issues)
-
Click Go to grafana button when done (username:
admin, password:admin). The button will be shown on the Trigger Collection page when data collection has finished.
Setup cron job
Commonly, we have requirement to synchorize data periodly. We providered a tool called lake-cli to meet that requirement. Check lake-cli usage at here.
Otherwise, if you just want to use the cron job, please check docker-compose version at here
Deploy to TeamCode
- IMPORTANT: MAKE SURE config-ui service is protected on TeamCode Control Panel before you set it up, or your TOKEN/PASSWORD might leak
- The following Environment Variables are to be set for
config-uiservice:
GRAFANA_ENDPOINT=
Developer Setup
Requirements
- Docker
- Golang
- Make
- Mac (Already installed)
- Windows: Download
- Ubuntu:
sudo apt-get install build-essential
How to setup dev environment
-
Navigate to where you would like to install this project and clone the repository
git clone https://github.com/merico-dev/lake.git cd lake -
Install go packages
make install
-
Copy sample config files to new local file
cp .env.example .env
-
Start the docker containers
Make sure the docker application is running before this step
make compose
-
Run the project
make dev
-
You can now post to
/taskto create a data collection task for Gitlab plugin. For demo purpose, we pick an open-source project on Gitlab called ClearURLs. Its Gitlab project id is 6821549 (right under its project name).curl -XPOST 'localhost:8080/task' \ -H 'Content-Type: application/json' \ -d '[[{ "plugin": "gitlab", "options": { "projectId": 6821549 } }]]' -
Visualize the data in the Grafana Dashboard
From here you can see existing data visualized from collected & enriched data
- Navigate to http://localhost:3002 (username:
admin, password:admin) - You can also create/modify existing/save dashboards to
lake - For more info on working with Grafana in Dev Lake see Grafana Doc
- Navigate to http://localhost:3002 (username:
Tests
To run the tests: make test
Grafana
We use Grafana as a visualization tool to build charts for the data stored in our database. Using SQL queries we can add panels to build, save, and edit customized dashboards.
All the details on provisioning, and customizing a dashboard can be found in the Grafana Doc
Contributing
License
This project is licensed under Apache License 2.0 - see the LICENSE file for details
Need help?
Message us on Discord
FAQ
Q: When I run docker-compose up -d I get this error: "qemu: uncaught target signal 11 (Segmentation fault) - core dumped". How do I fix this?
A: Mac M1 users need to download a specific version of docker on their machine. You can find it here: https://docs.docker.com/desktop/mac/apple-silicon/