Open Source Project Criticality Score (Beta)
This project is maintained by members of the Securing Critical Projects WG.
Goals
-
Generate a criticality score for every open source project.
-
Create a list of critical projects that the open source community depends on.
-
Use this data to proactively improve the security posture of these critical projects.
Criticality Score
A project's criticality score defines the influence and importance of a project. It is a number between 0 (least-critical) and 1 (most-critical). It is based on the following algorithm by Rob Pike:
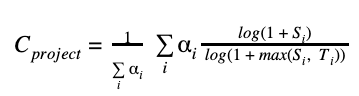
We use the following parameters to derive the criticality score for an open source project:
| Parameter (Si) | Weight (αi) | Max threshold (Ti) | Description | Reasoning |
|---|---|---|---|---|
| created_since | 1 | 120 | Time since the project was created (in months) | Older project has higher chance of being widely used or being dependent upon. |
| updated_since | -1 | 120 | Time since the project was last updated (in months) | Unmaintained projects with no recent commits have higher chance of being less relied upon. |
| contributor_count | 2 | 5000 | Count of project contributors (with commits) | Different contributors involvement indicates project's importance. |
| org_count | 1 | 10 | Count of distinct organizations that contributors belong to | Indicates cross-organization dependency. |
| commit_frequency | 1 | 1000 | Average number of commits per week in the last year | Higher code churn has slight indication of project's importance. Also, higher susceptibility to vulnerabilities. |
| recent_releases_count | 0.5 | 26 | Number of releases in the last year | Frequent releases indicates user dependency. Lower weight since this is not always used. |
| closed_issues_count | 0.5 | 5000 | Number of issues closed in the last 90 days | Indicates high contributor involvement and focus on closing user issues. Lower weight since it is dependent on project contributors. |
| updated_issues_count | 0.5 | 5000 | Number of issues updated in the last 90 days | Indicates high contributor involvement. Lower weight since it is dependent on project contributors. |
| comment_frequency | 1 | 15 | Average number of comments per issue in the last 90 days | Indicates high user activity and dependence. |
| dependents_count | 2 | 500000 | Number of project mentions in the commit messages | Indicates repository use, usually in version rolls. This parameter works across all languages, including C/C++ that don't have package dependency graphs (though hack-ish). Plan to add package dependency trees in the near future. |
NOTE:
- We are looking for community ideas to improve upon these parameters.
- There will always be exceptions to the individual reasoning rules.
Usage
The program only requires one argument to run, the name of the repo:
$ pip3 install criticality-score
$ criticality_score --repo github.com/kubernetes/kubernetes
name: kubernetes
url: https://github.com/kubernetes/kubernetes
language: Go
created_since: 79
updated_since: 0
contributor_count: 3664
org_count: 5
commit_frequency: 102.7
recent_releases_count: 76
closed_issues_count: 2906
updated_issues_count: 5136
comment_frequency: 5.7
dependents_count: 407254
criticality_score: 0.9862
You can add your own parameters to the criticality score calculation. For example, you can add internal project usage data to re-adjust the project's criticality score for your prioritization needs. This can be done by adding the --params argument on the command line.
Authentication
Before running criticality score, you need to:
- For GitHub repos, you need to create a GitHub access token and set it in environment variable
GITHUB_AUTH_TOKEN. This helps to avoid the GitHub's api rate limits with unauthenticated requests.
# For posix platforms, e.g. linux, mac:
export GITHUB_AUTH_TOKEN=<your access token>
# For windows:
set GITHUB_AUTH_TOKEN=<your access token>
- For GitLab repos, you need to create a GitLab access token and set it in environment variable
GITLAB_AUTH_TOKEN. This helps to avoid the GitLab's api limitations for unauthenticated users.
# For posix platforms, e.g. linux, mac:
export GITLAB_AUTH_TOKEN=<your access token>
# For windows:
set GITLAB_AUTH_TOKEN=<your access token>
Formatting Results
There are three formats currently: default, json, and csv. Others may be added in the future.
These may be specified with the --format flag.
Public Data
If you're only interested in seeing a list of critical projects with their criticality score, we publish them in csv format.
This data is available on Google Cloud Storage and can be downloaded via the gsutil command-line tool or the web browser here.
NOTE: Currently, these lists are derived from projects hosted on GitHub ONLY. We do plan to expand them in near future to account for projects hosted on other source control systems.
$ gsutil ls gs://ossf-criticality-score/*.csv
gs://ossf-criticality-score/c_top_200.csv
gs://ossf-criticality-score/cplusplus_top_200.csv
gs://ossf-criticality-score/csharp_top_200.csv
gs://ossf-criticality-score/go_top_200.csv
gs://ossf-criticality-score/java_top_200.csv
gs://ossf-criticality-score/js_top_200.csv
gs://ossf-criticality-score/php_top_200.csv
gs://ossf-criticality-score/python_top_200.csv
gs://ossf-criticality-score/ruby_top_200.csv
gs://ossf-criticality-score/rust_top_200.csv
gs://ossf-criticality-score/shell_top_200.csv
This data is generated using this generator script. For example, to generate a list of top 200 C language projects, run:
$ pip3 install python-gitlab PyGithub
$ python3 -u -m criticality_score.generate \
--language c --count 200 --sample-size 5000 --output-dir output
We have also aggregated the results over 100K repositories in GitHub (language-independent) and are available for download here.
Contributing
If you want to get involved or have ideas you'd like to chat about, we discuss this project in the Securing Critical Projects WG meetings.
See the Community Calendar for the schedule and meeting invitations.
See the Contributing documentation for guidance on how to contribute.





















