Cog: Standard machine learning models
Define your models in a standard format, store them in a central place, run them anywhere.
- Standard interface for a model. Define all your models with Cog, in a standard format. It's not just the graph – it also includes code, pre-/post-processing, data types, Python dependencies, system dependencies – everything.
- Store models in a central place. No more hunting for the right model file on S3. Cog models are in one place with a content-addressable ID.
- Run models anywhere: Cog models run anywhere Docker runs: your laptop, Kubernetes, cloud platforms, batch processing pipelines, etc. And, you can use adapters to convert the models to on-device formats.
Cog does a few things to make your life easier:
- Automatic Docker image. Define your environment with a simple format, and Cog will generate CPU and GPU Docker images using best practices and efficient base images.
- Automatic HTTP service. Cog will generate an HTTP service from the definition of your model, so you don't need to write a Flask server in the right way.
- No more CUDA hell. Cog knows which CUDA/cuDNN/PyTorch/Tensorflow/Python combos are compatible and will pick the right versions for you.
How does it work?
- Define how inferences are run on your model:
import cog
import torch
class ColorizationModel(cog.Model):
def setup(self):
self.model = torch.load("./weights.pth")
@cog.input("input", type=Path, help="Grayscale input image")
def run(self, input):
# ... pre-processing ...
output = self.model(processed_input)
# ... post-processing ...
return processed_output
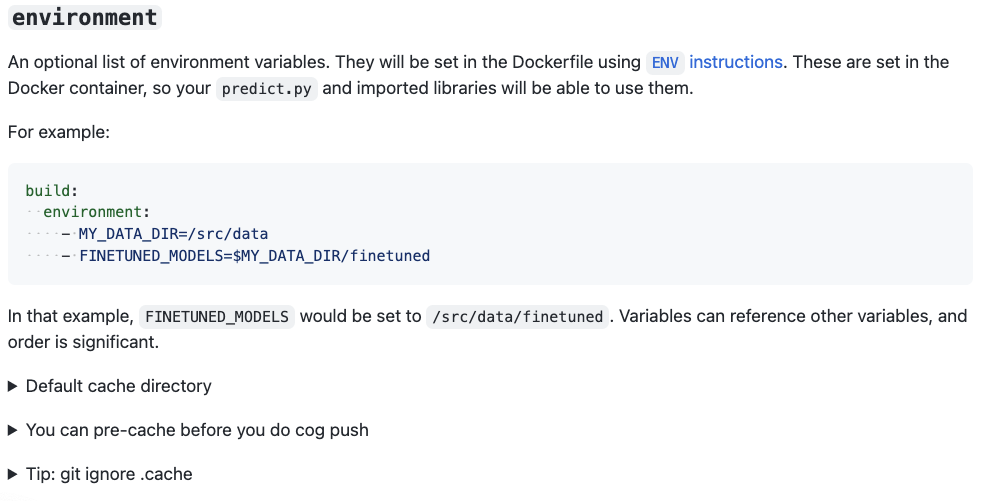
- Define the environment it runs in with
cog.yaml:
model: "model.py:ColorizationModel"
environment:
python_version: "3.8"
python_requirements: "requirements.txt"
system_packages:
- libgl1-mesa-glx
- libglib2.0-0
- Push it to a repository and build it:
$ cog build
--> Uploading '.' to repository http://10.1.2.3/colorization... done
--> Building CPU Docker image... done
--> Building GPU Docker image... done
--> Built model b6a2f8a2d2ff
This has:
- Created a ZIP file containing your code + weights + environment definition, and assigned it a content-addressable SHA256 ID.
- Pushed this ZIP file up to a central repository so it never gets lost and can be run by anyone.
- Built two Docker images (one for CPU and one for GPU) that contains the model in a reproducible environment, with the correct versions of Python, your dependencies, CUDA, etc.
Now, anyone who has access to this repository can run inferences on this model:
$ cog infer b6a2f8a2d2ff -i @input.png -o @output.png
--> Pulling GPU Docker image for b6a2f8a2d2ff... done
--> Running inference... done
--> Written output to output.png
It is also just a Docker image, so you can run it as an HTTP service wherever Docker runs:
$ cog show b6a2f8a2d2ff
...
Docker image (GPU): registry.hooli.net/colorization:b6a2f8a2d2ff-gpu
Docker image (CPU): registry.hooli.net/colorization:b6a2f8a2d2ff-cpu
$ docker run -d -p 8000:8000 --gpus all registry.hooli.net/colorization:b6a2f8a2d2ff-gpu
$ curl http://localhost:8000/infer -F [email protected]
Why are we building this?
It's really hard for researchers to ship machine learning models to production. Dockerfiles, pre-/post-processing, API servers, CUDA versions. More often than not the researcher has to sit down with an engineer to get the damn thing deployed.
By defining a standard model, all that complexity is wrapped up behind a standard interface. Other systems in your machine learning stack just need to support Cog models and they'll be able to run anything a researcher dreams up.
At Spotify, we built a system like this for deploying audio deep learning models. We realized this was a repeating pattern: Uber, Coinbase, and others have built similar systems. So, we're making an open source version.
The hard part is defining a model interface that works for everyone. We're releasing this early so we can get feedback on the design and find collaborators. Hit us up if you're interested in using it or want to collaborate with us. We're on Discord or email us at [email protected].
Install
No binaries yet! You'll need Go 1.16, then run:
make install
This installs the cog binary to $GOPATH/bin/cog.
Next steps
- Get started with an example model
- Take a look at some examples of using Cog
- Python reference to learn how the
cog.Modelinterface works cog.yamlreference to learn how to define your model's envrionment- Server documention, if you want to integrate directly with the Cog server