



rosedb is an embedded and fast k-v database based on LSM + WAL, so it has pretty good write performance and high throughput. It also supports many kinds of data structures such as string, list, hash, set, zset,and the API name style is similar to Redis.
rosedb is in pure Go, simple and easy to understand for using or learning.
Feature
- Support rich data structures :
string,list,hash,set,zset. - Easy to embedded (
import "github.com/roseduan/rosedb"). - Low latency and high throughput.
- Operations of various data types can be parallel.
- Has builtin rosedb-cli for command line, also support redis-cli.
- Support expiration and TTL.
Usage
Cli example
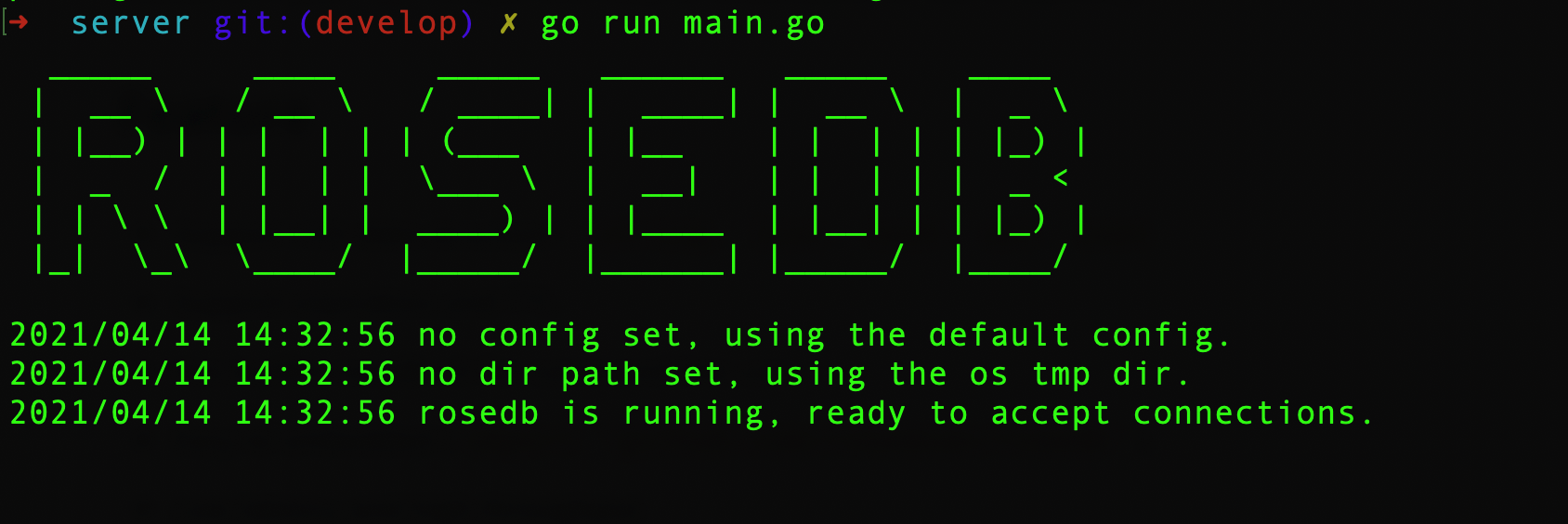
Change the directory to rosedb/cmd/server.
Run the main.go
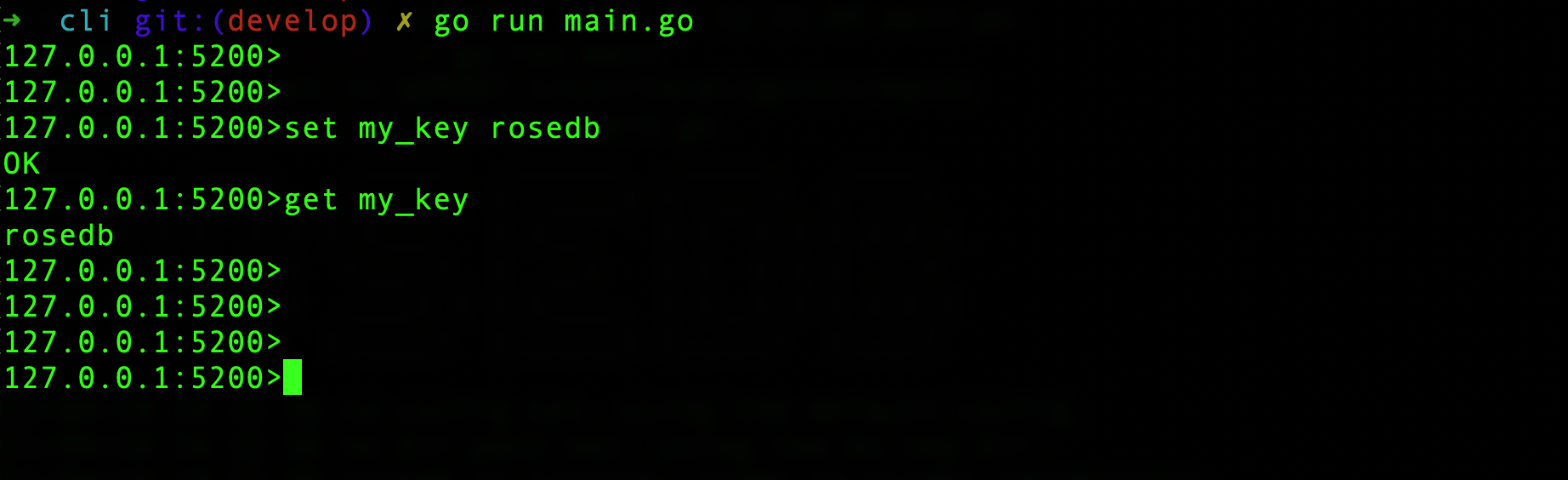
Open a new shell, and change the directory to rosedb/cmd/cli, and run the main.go:
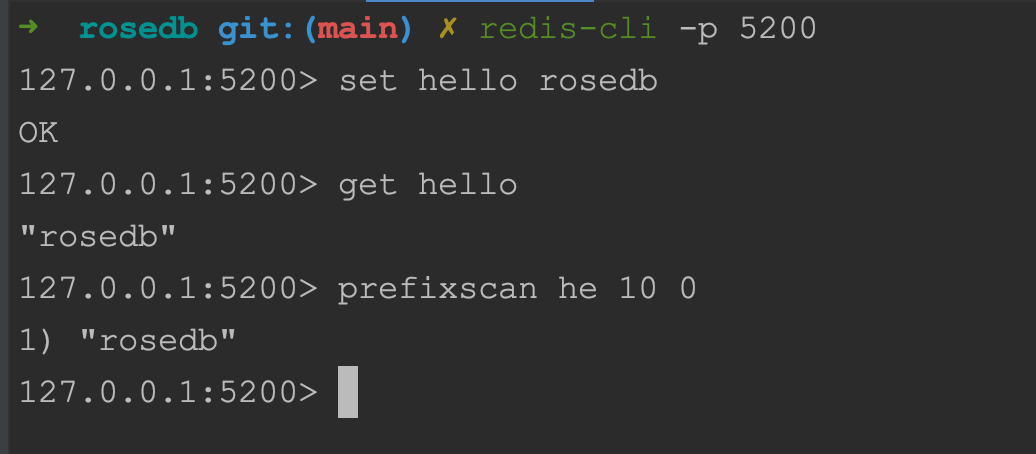
Or you can just use redis-cli or any other redis client:
Embedded example
Import rosedb in the application:
import "github.com/roseduan/rosedb"
And open a database:
package main
import (
"github.com/roseduan/rosedb"
"log"
)
func main() {
config := rosedb.DefaultConfig()
db, err := rosedb.Open(config)
if err != nil {
log.Fatal(err)
}
// don`t forget to close!
defer db.Close()
//...
}
Command
String
- Set
- SetNx
- Get
- GetSet
- Append
- StrLen
- StrExists
- StrRem
- PrefixScan
- RangeScan
- Expire
- Persist
- TTL
List
- LPush
- RPush
- LPop
- RPop
- LIndex
- LRem
- LInsert
- LSet
- LTrim
- LRange
- LLen
Hash
- HSet
- HSetNx
- HGet
- HGetAll
- HDel
- HExists
- HLen
- HKeys
- HValues
Set
- SAdd
- SPop
- SIsMember
- SRandMember
- SRem
- SMove
- SCard
- SMembers
- SUnion
- SDiff
Zset
- ZAdd
- ZScore
- ZCard
- ZRank
- ZRevRank
- ZIncrBy
- ZRange
- ZRevRange
- ZRem
- ZGetByRank
- ZRevGetByRank
- ZScoreRange
- ZRevScoreRange
TODO
- Support expiration and TTL
- Add prefix scan and range scan for string type
- Cli for command line use
- Improve the performance of reopening db.
- Improve the performance of reclaim operation.
- Support transaction, ACID features
- Compress the written data
- Add cache elimination strategy (Such as LRU, LFU, Random, etc...)
- Improve related documents
Benchmark
Benchmark Environment
-
Go version:1.14.4
-
System: macOS Catalina 10.15.7
-
CPU: 2.6GHz 6-Core Intel Core i7
-
Memory: 16 GB 2667 MHz DDR4
-
The test databases I choose:
- Badger
- GoLevelDB
- Pudge
Benchmark Result
execute 100w times
go test -bench=. -benchtime=1000000x
badger 2021/05/16 21:59:53 INFO: All 0 tables opened in 0s
badger 2021/05/16 21:59:53 INFO: Discard stats nextEmptySlot: 0
badger 2021/05/16 21:59:53 INFO: Set nextTxnTs to 0
goos: darwin
goarch: amd64
pkg: rosedb-bench
BenchmarkPutValue_BadgerDB-12 1000000 11518 ns/op 2110 B/op 46 allocs/op
BenchmarkGetValue_BadgerDB-12 1000000 3547 ns/op 1172 B/op 20 allocs/op
BenchmarkPutValue_GoLevelDB-12 1000000 4659 ns/op 352 B/op 9 allocs/op
BenchmarkGetValue_GoLevelDB-12 1000000 2838 ns/op 814 B/op 13 allocs/op
BenchmarkPutValue_Pudge-12 1000000 8512 ns/op 791 B/op 22 allocs/op
BenchmarkGetValue_Pudge-12 1000000 1253 ns/op 200 B/op 6 allocs/op
BenchmarkPutValue_RoseDB_KeyValRam-12 1000000 4371 ns/op 566 B/op 11 allocs/op
BenchmarkGetValue_RoseDB_KeyValRam-12 1000000 481 ns/op 56 B/op 3 allocs/op
BenchmarkPutValue_RoseDB_KeyOnlyRam-12 1000000 4255 ns/op 566 B/op 11 allocs/op
BenchmarkGetValue_RoseDB_KeyOnlyRam-12 1000000 2986 ns/op 312 B/op 8 allocs/op
PASS
ok rosedb-bench 46.388s
execute 250w times
go test -bench=. -benchtime=2500000x
badger 2021/05/16 22:06:08 INFO: All 0 tables opened in 0s
badger 2021/05/16 22:06:08 INFO: Discard stats nextEmptySlot: 0
badger 2021/05/16 22:06:08 INFO: Set nextTxnTs to 0
goos: darwin
goarch: amd64
pkg: rosedb-bench
BenchmarkPutValue_BadgerDB-12 2500000 11660 ns/op 2150 B/op 46 allocs/op
BenchmarkGetValue_BadgerDB-12 2500000 4180 ns/op 1222 B/op 21 allocs/op
BenchmarkPutValue_GoLevelDB-12 2500000 4637 ns/op 336 B/op 9 allocs/op
BenchmarkGetValue_GoLevelDB-12 2500000 2942 ns/op 817 B/op 14 allocs/op
BenchmarkPutValue_Pudge-12 2500000 9238 ns/op 763 B/op 22 allocs/op
BenchmarkGetValue_Pudge-12 2500000 1275 ns/op 200 B/op 6 allocs/op
BenchmarkPutValue_RoseDB_KeyValRam-12 2500000 4474 ns/op 566 B/op 11 allocs/op
BenchmarkGetValue_RoseDB_KeyValRam-12 2500000 525 ns/op 56 B/op 3 allocs/op
BenchmarkPutValue_RoseDB_KeyOnlyRam-12 2500000 4294 ns/op 566 B/op 11 allocs/op
BenchmarkGetValue_RoseDB_KeyOnlyRam-12 2500000 3038 ns/op 312 B/op 8 allocs/op
PASS
ok rosedb-bench 119.529s
Benchmark Conclusion
Badger
Its read and wirte performance are stable. Write: 11000+ ns/op. Read: 4000+ ns/op.
GoLevelDB
Its write performance is almost 2.5x faster than Badger, and its read performance is almost 3000 ns/op, a little faster than Badger.
Pudge
Its write performance is between GoLevelDB and Badger, almost 8500 ns/op, slower than GoLevelDB. Its read performance is very fast and stable, almost 2x faster than GoLevelDB.
RoseDB
Its write performance is stable, alomost the same as GoLevelDB, 2.5x faster than Badger.
In KeyValueRamMode, since the values are all in memory, so it is the fastest of all.
In KeyOnlyRamMode, it is almost the same as GoLevelDB.
Contributing
If you are intrested in contributing to rosedb, please see here: CONTRIBUTING
Contact me
If you have any questions, you can contact me by email: [email protected]
License
rosedb is licensed under the term of the MIT License












