html-to-markdown


![]()
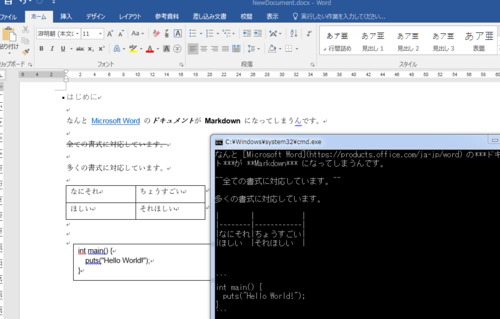
Convert HTML into Markdown with Go. It is using an HTML Parser to avoid the use of regexp as much as possible. That should prevent some weird cases and allows it to be used for cases where the input is totally unknown.
Installation
go get github.com/JohannesKaufmann/html-to-markdown
Usage
import md "github.com/JohannesKaufmann/html-to-markdown"
converter := md.NewConverter("", true, nil)
html = `<strong>Important</strong>`
markdown, err := converter.ConvertString(html)
if err != nil {
log.Fatal(err)
}
fmt.Println("md ->", markdown)
If you are already using goquery you can pass a selection to Convert.
markdown, err := converter.Convert(selec)
Using it on the command line
If you want to make use of html-to-markdown on the command line without any Go coding, check out html2md, a cli wrapper for html-to-markdown that has all the following options and plugins builtin.
Options
The third parameter to md.NewConverter is *md.Options.
For example you can change the character that is around a bold text ("**") to a different one (for example "__") by changing the value of StrongDelimiter.
opt := &md.Options{
StrongDelimiter: "__", // default: **
// ...
}
converter := md.NewConverter("", true, opt)
For all the possible options look at godocs and for a example look at the example.
Adding Rules
converter.AddRules(
md.Rule{
Filter: []string{"del", "s", "strike"},
Replacement: func(content string, selec *goquery.Selection, opt *md.Options) *string {
// You need to return a pointer to a string (md.String is just a helper function).
// If you return nil the next function for that html element
// will be picked. For example you could only convert an element
// if it has a certain class name and fallback if not.
content = strings.TrimSpace(content)
return md.String("~" + content + "~")
},
},
// more rules
)
For more information have a look at the example add_rules.
Using Plugins
If you want plugins (github flavored markdown like striketrough, tables, ...) you can pass it to Use.
import "github.com/JohannesKaufmann/html-to-markdown/plugin"
// Use the `GitHubFlavored` plugin from the `plugin` package.
converter.Use(plugin.GitHubFlavored())
Or if you only want to use the Strikethrough plugin. You can change the character that distinguishes the text that is crossed out by setting the first argument to a different value (for example "~~" instead of "~").
converter.Use(plugin.Strikethrough(""))
For more information have a look at the example github_flavored.
Writing Plugins
Have a look at the plugin folder for a reference implementation. The most basic one is Strikethrough.
Other Methods
func (c *Converter) Keep(tags ...string) *Converter
Determines which elements are to be kept and rendered as HTML.
func (c *Converter) Remove(tags ...string) *Converter
Determines which elements are to be removed altogether i.e. converted to an empty string.
Issues
If you find HTML snippets (or even full websites) that don't produce the expected results, please open an issue!
Related Projects
- turndown (js), a very good library written in javascript.
- lunny/html2md, which is using regex instead of goquery. I came around a few edge case when using it (leaving some html comments, ...) so I wrote my own.