Filter By
86 Resources
Golang Web Crawling
Elegant Scraper and Crawler Framework for Golang
Colly Lightning Fast and Elegant Scraping Framework for Gophers Colly provides a clean interface to write any kind of crawler/scraper/spider. With Col
Web Scraper in Go, similar to BeautifulSoup
soup Web Scraper in Go, similar to BeautifulSoup soup is a small web scraper package for Go, with its interface highly similar to that of BeautifulSou
Distributed web crawler admin platform for spiders management regardless of languages and frameworks. 分布式爬虫管理平台,支持任何语言和框架
Crawlab 中文 | English Installation | Run | Screenshot | Architecture | Integration | Compare | Community & Sponsorship | CHANGELOG | Disclaimer Golang-
Journalist. An RSS aggregator.

Journalist. An RSS aggregator. Download the latest version for macOS, Linux, FreeBSD, NetBSD, OpenBSD & Plan9 here. WARNING: journalist is highly expe
[爬虫框架 (golang)] An awesome Go concurrent Crawler(spider) framework. The crawler is flexible and modular. It can be expanded to an Individualized crawler easily or you can use the default crawl components only.
go_spider A crawler of vertical communities achieved by GOLANG. Latest stable Release: Version 1.2 (Sep 23, 2014). QQ群号:337344607 Features Concurrent
Crawls web pages and prints any link it can find.
crawley Crawls web pages and prints any link it can find. Scan depth (by default - 0) can be configured. features fast SAX-parser (powered by golang.o
Declarative web scraping
Ferret Try it! Docs CLI Test runner Web worker What is it? ferret is a web scraping system. It aims to simplify data extraction from the web for UI te
QQ空间(Qzone)爬虫,手机扫描登陆后即可并发下载相册的相片/视频

qq-zone QQ空间爬虫,多协程并发下载相册的相片/视频 前言 QQ相册可以说是存放了好大一部分人生活的点点滴滴,近段时间发现QQ空间莫名会删除短视频或者相片,记得20年的时候也类似新闻报道过,为了快速备份写了此程序,网上看到大部分是使用Python实现的,而且操作过程也都比较繁琐,需要打开网页
A little like that j-thing, only in Go.
goquery - a little like that j-thing, only in Go goquery brings a syntax and a set of features similar to jQuery to the Go language. It is based on Go
Gospider - Fast web spider written in Go

GoSpider GoSpider - Fast web spider written in Go Painless integrate Gospider into your recon workflow? Enjoying this tool? Support it's development a
ant (alpha) is a web crawler for Go.
The package includes functions that can scan data from the page into your structs or slice of structs, this allows you to reduce the noise and complexity in your source-code.
Pholcus is a distributed high-concurrency crawler software written in pure golang

Pholcus Pholcus(幽灵蛛)是一款纯 Go 语言编写的支持分布式的高并发爬虫软件,仅用于编程学习与研究。 它支持单机、服务端、客户端三种运行模式,拥有Web、GUI、命令行三种操作界面;规则简单灵活、批量任务并发、输出方式丰富(mysql/mongodb/kafka/csv/excel等
Download Vimeo videos and retrieve metadata in Go.
vimego Download Vimeo videos and retrieve metadata. Largely based on yashrathi's vimeo_downloader. Installing go get github.com/raitonoberu/vimego Ple
crawlergo is a browser crawler that uses chrome headless mode for URL collection.

A powerful browser crawler for web vulnerability scanners
Fetch web pages using headless Chrome, storing all fetched resources including JavaScript files
Fetch web pages using headless Chrome, storing all fetched resources including JavaScript files. Run arbitrary JavaScript on many web pages and see the returned values

这是一个使用Go语言开发的迷你定向抓取器,实现对种子链接的抓取,并把URL长相符合特定正则表达式的网页保存到磁盘上。
项目名称 mini-spider 背景 在调研过程中,经常需要对一些网站进行定向抓取。这是一个使用Go语言开发的迷你定向抓取器,实现对种子链接的抓取,并把URL长相符合特定正则表达式的网页保存到磁盘上。 主要功能 实现对种子链接的爬取,并把URL符合特定正则表达式的网页保存到磁盘上。 快速开始 构建
Apollo 💎 A Unix-style personal search engine and web crawler for your digital footprint.

Apollo 💎 A Unix-style personal search engine and web crawler for your digital footprint Demo apollodemo.mp4 Contents Background Thesis Design Archite
Fast website link checker in Go

Muffet Muffet is a website link checker which scrapes and inspects all pages in a website recursively. Features Massive speed Colored outputs Differen
go版本jd_seckill,京东茅台抢购,降低使用门栏。
Jd_Seckill ⚠ 此项目是python jd_seckill 的go版本实现,旨在降低使用门栏和相互学习而创建。 特别声明: 本仓库发布的jd_seckill项目中涉及的任何脚本,仅用于测试和学习研究,禁止用于商业用途,不能保证其合法性,准确性,完整性和有效性,请根据情况自行判断。
High-performance crawler framework based on fasthttp.
predator / 掠食者 基于 fasthttp 开发的高性能爬虫框架 使用 下面是一个示例,基本包含了当前已完成的所有功能,使用方法可以参考注释。 1 创建一个 Crawler import "github.com/go-predator/predator" func main() {
DataHen Till is a standalone tool that instantly makes your existing web scraper scalable, maintainable, and more unblockable, with minimal code changes on your scraper.

DataHen Till is a standalone tool that instantly makes your existing web scraper scalable, maintainable, and more unblockable, with minimal code changes on your scraper.
Go-Yahoo-Finance-Daily-Actives - Scrape for the daily actives on yh Finance and save the data to a CSV, and optionally send it to yourself as an email

Go-Yahoo-Finance-Daily-Actives - Scrape for the daily actives on yh Finance and save the data to a CSV, and optionally send it to yourself as an email
Downloader for saved Reddit images
ErGo Downloader Downloader for saved Reddit images Features Downloads saved images from your Reddit account Optionally unsaves them automatically Opti
ziroom自如新房上架钉钉提醒

自如新房源实时提醒 利用自如网页版查询房源,解析HTML并分析房源,找到新上架房源并推送至钉钉群。 首次初始化加载所选链接的所有房源(不通知) 等待下次任务调度,调度周期时间由taskInterval控制 执行任务,拿到最新房源数据,与上次房源集合进行比对 已存在房源pass,新房源通知钉钉 第一步
利用天眼查查询企业子公司
cSubsidiary 利用天眼查查询企业子公司 下载地址 介绍 可以通过两种方式查询自己想要的企业子公司 -n 参数:利用给出的关键字先进行模糊查询,然后选出第一个匹配的结果,对该公司进行查询。(方便但是不准确,所以不推荐) -i 参数:利用给出的公司id对该公司进行查询。
Elektra-Auto-Checkout - Utilities to assist in checkout automation of various commercial and retail sites
Elektra About This Project Elektra is designed to automate the process of invent
:paw_prints: Creeper - The Next Generation Crawler Framework (Go)

About Creeper is a next-generation crawler which fetches web page by creeper script. As a cross-platform embedded crawler, you can use it for your new
skweez spiders web pages and extracts words for wordlist generation.
skweez skweez (pronounced like "squeeze") spiders web pages and extracts words for wordlist generation. It is basically an attempt to make a more oper
轻量级爬虫,接口测试,压力测试框架, 提高开发对应场景的golang程序的效率。
gathertool 轻量级爬虫,接口测试,压力测试框架, 提高开发对应场景的golang程序的效率。
Fast, highly configurable, cloud native dark web crawler.
Bathyscaphe dark web crawler Bathyscaphe is a Go written, fast, highly configurable, cloud-native dark web crawler. How to start the crawler To start
Collyzar - A distributed redis-based framework for colly.
Collyzar A distributed redis-based framework for colly. Collyzar provides a very simple configuration and tools to implement distributed crawling/scra
DorkScout - Golang tool to automate google dork scan against the entiere internet or specific targets
dorkscout dokrscout is a tool to automate the finding of vulnerable applications or secret files around the internet throught google searches, dorksco
Best Room Price Scraper from Booking.com
Best Room Price Scraper from Booking.com This repo is a tutorial of Large Scale
Go-based search engine URL collector , support Google, Bing, can be based on Google syntax batch collection URL

Go-based search engine URL collector , support Google, Bing, can be based on Google syntax batch collection URL
Interact with Chromium-based browsers' debug port to view open tabs, installed extensions, and cookies

WhiteChocolateMacademiaNut Description Interacts with Chromium-based browsers' debug port to view open tabs, installed extensions, and cookies. Tested
🔎 scan the internet to find "private" proxies.
🔎 scan the internet to find "private" proxies. 🧠 HTTP/SOCKS4/SOCKS5 Proxies. 📌 Installation: - sudo apt-get install git zmap golang
Cirno-go A tool for downloading books from hbooker in Go.

Cirno-go A tool for downloading books from hbooker in Go. Features Login your own account Search books by book name Download books as txt and epub fil
抖音(中国区)无水印视频、背景音乐、作者ID、作者昵称、作品标题等的全能解析和下载
DouYinBot 抖音(中国区)无水印视频、背景音乐、作者ID、作者昵称、作品标题等的全能解析和下载。 写在前面 本项目纯属个人爱好创作 所有视频的版权始终属于「字节跳动」 严禁用于任何商业用途,如果构成侵权概不负责 目前功能 解析无水印视频 解析视频标题 解析作者昵称 解析作者ID 不需要去除多
Golang based web site opengraph data scraper with caching

Snapper A Web microservice for capturing a website's OpenGraph data built in Golang Building Snapper building the binary git clone https://github.com/
用Go实现抓取Boss直聘职位数据。IP代理,模拟浏览器,高效快速。

crawler-boss 用Go实现抓取Boss直聘职位数据。有几个特点 1.代理防IP被封 2.模拟浏览器,反识别爬虫。 3.控制爬取频率。 4.多协程爬取。 不足之处 1.爬取失败,没有进行重试以及更换IP处理。 2.错误处理 3.代码结构方面进行优化。 交流 && 疑问 如果有任何错误或不懂的
Just a web crawler
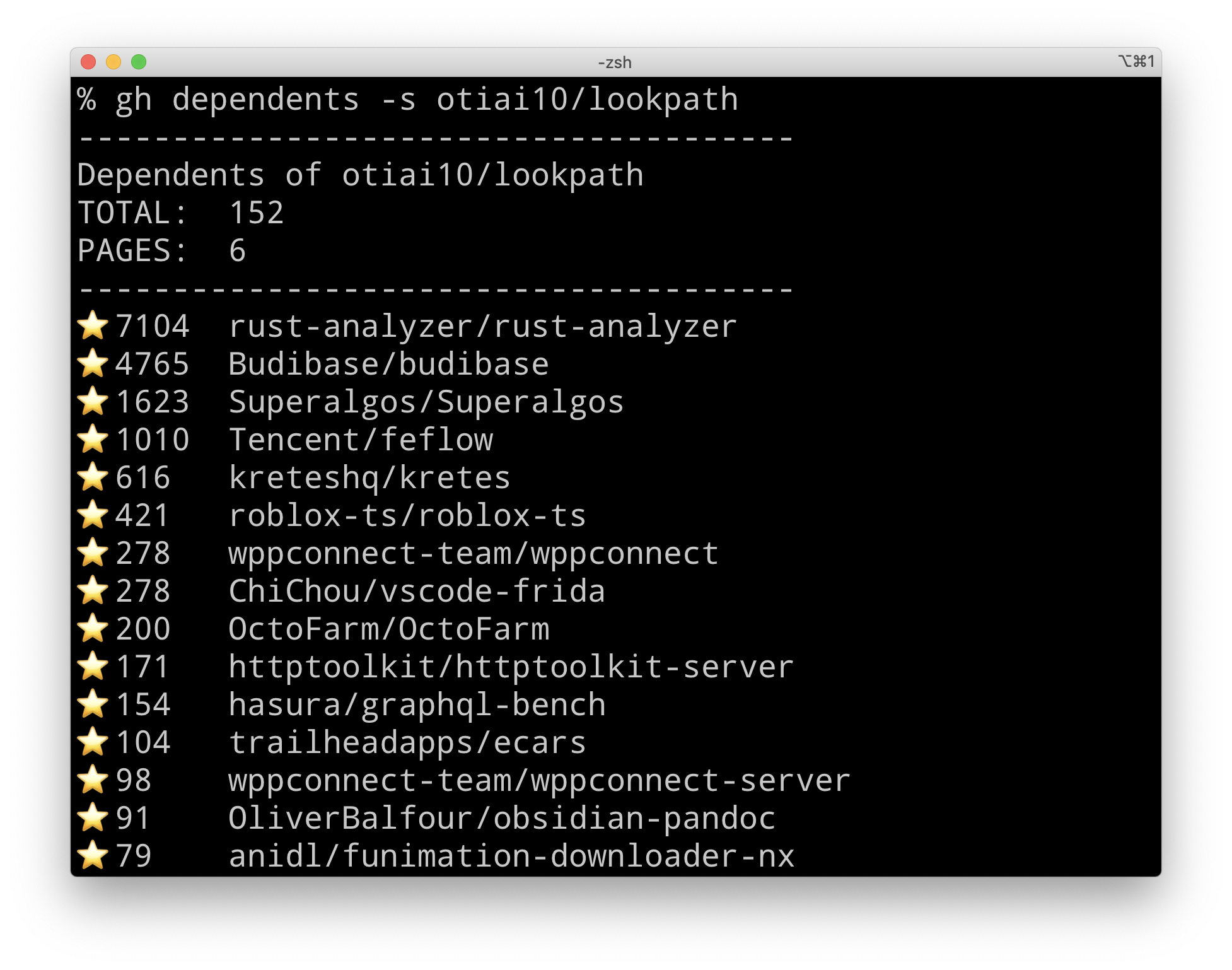
gh-dependents gh command extension to see dependents of your repository. See The GitHub Blog: GitHub CLI 2.0 includes extensions! Install gh extension
Fast golang web crawler for gathering URLs and JavaSript file locations.
Fast golang web crawler for gathering URLs and JavaSript file locations. This is basically a simple implementation of the awesome Gocolly library.
New World Auction House Crawler In Golang
New-World-Auction-House-Crawler Goal of this library is to have a process which grabs New World auction house data in the background while playing the
A crawler/scraper based on golang + colly, configurable via JSON
A crawler/scraper based on golang + colly, configurable via JSON
A crawler/scraper based on golang + colly, configurable via JSON
Super-Simple Scraper This a very thin layer on top of Colly which allows configuration from a JSON file. The output is JSONL which is ready to be impo
A Golang library to scrape lyrics from musixmatch.com (WIP)
A Golang library to scrape lyrics from musixmatch.com (WIP)
Go IMDb Crawler
Go IMDb Crawler Hit the ⭐ button to show some ❤️ 😃 INSPIRATION 💪 Want to know which celebrities have a common birthday with yours? 👀 Want to get th
🦙 acao(阿草), the tool man for data scraping of https://asoul.video/.
🦙 acao acao(阿草), the tool man for data scraping of https://asoul.video/. Deploy to Aliyun serverless function with Raika update_member Update A-SOUL
A simple scraper to export data from buildkite to honeycomb using opentelemetry SDK
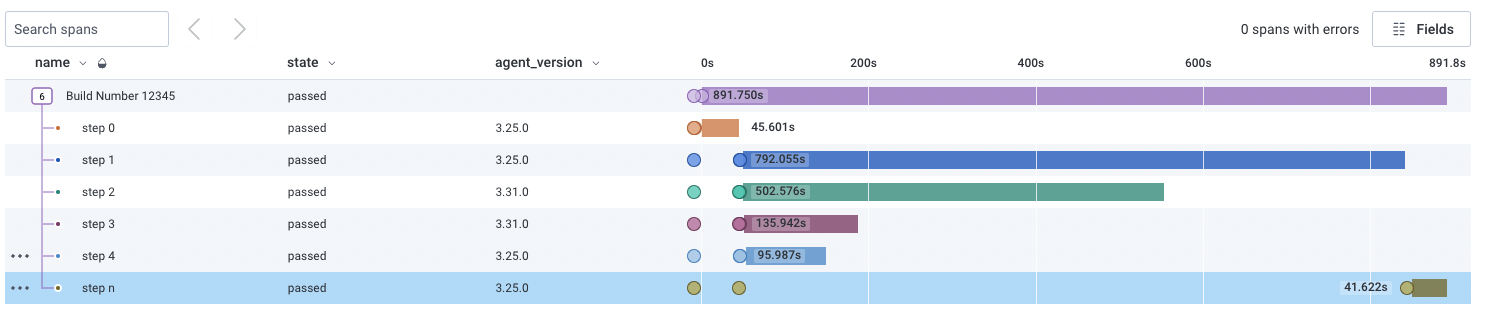
A quick scraper program that let you export builds on BuildKite as OpenTelemetry data and then send them to honeycomb.io for slice-n-dice high cardinality analysis.
用go写的小工具,可以合并抓包文件中的TCP数据部分,可用于下载抖音短视频

功能 对wireshark生成的抓包文件进行解析,整合TCP数据部分 可用于获取抖音短视频,得到的视频码率为原始码率,并且不带水印 原理 逐一读取.pcap文件的TCP包,按照源目地址进行归类,将服务端返回的数据排序后写入文件 代码内附大量注释,简单易懂。