Faktory 




At a high level, Faktory is a work server. It is the repository for background jobs within your application. Jobs have a type and a set of arguments and are placed into queues for workers to fetch and execute.
You can use this server to distribute jobs to one or hundreds of machines. Jobs can be executed with any language by clients using the Faktory API to fetch a job from a queue.
Basic Features
- Jobs are represented as JSON hashes.
- Jobs are pushed to and fetched from queues.
- Jobs are reserved with a timeout, 30 min by default.
- Jobs
FAIL'd or notACK'd within the reservation timeout are requeued. - FAIL'd jobs trigger a retry workflow with exponential backoff.
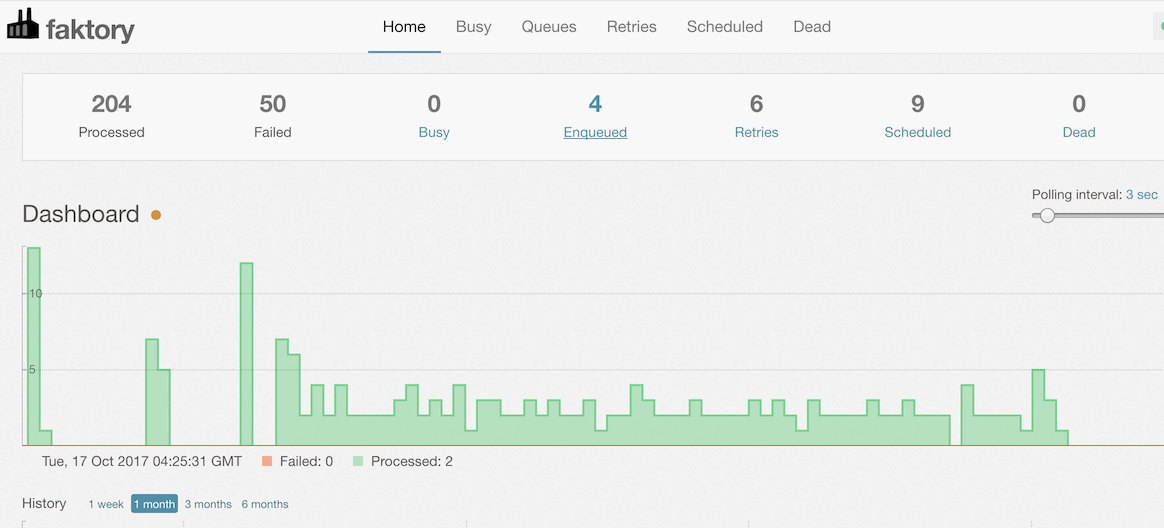
- Contains a comprehensive Web UI for management and monitoring.
Installation
See the Installation wiki page for current installation methods. Here's more info on installation with Docker and AWS ECS.
Documentation
Please see the Faktory wiki for full documentation.
Support
You can find help in the contribsys/faktory chat channel. Stop by and say hi!
Author
Mike Perham, @getajobmike, mike @ contribsys.com