English | 简体中文
SuperEdge
What is SuperEdge?
SuperEdge is an open source container management system for edge computing to manage compute resources and container applications in multiple edge regions. These resources and applications, in the current approach, are managed as one single Kubernetes cluster. A native Kubernetes cluster can be easily converted to a SuperEdge cluster.
SuperEdge has the following characteristics:
- Kubernetes-native: SuperEdge extends the powerful container orchestration and scheduling capabilities of Kubernetes to the edge. It makes nonintrusive enhancements to Kubernetes and is fully compatible with all Kubernetes APIs and resources. Kubernetes users can leverage SuperEdge easily for edge environments with minimal learning.
- Edge autonomy: SuperEdge provides L3 edge autonomy. When the network connection between the edge and the cloud is unstable, or the edge node is offline, the node can still work independently. This eliminates the negative impact of unreliable network.
- Distributed node health monitoring: SuperEdge provides edge-side health monitoring capabilities. SuperEdge can continue to monitor the processes on the edge side and collect health information for faster and more accurate problem discovery and reporting. In addition, its distributed design can provide multi-region monitoring and management.
- Built-in edge orchestration capability: SuperEdge supports automatic deployment of multi-regional microservices. Edge-side services are closed-looped, and it effectively reduces the operational overhead and improves the fault tolerance and availability of the system.
- Network tunneling: SuperEdge ensures that Kubernetes nodes can operate under different network situations. It supports network tunnelling using TCP, HTTP and HTTPS.
SuperEdge was initiated by the following companies: Tencent, Intel, VMware, Huya, Cambricon, Captialonline and Meituan.
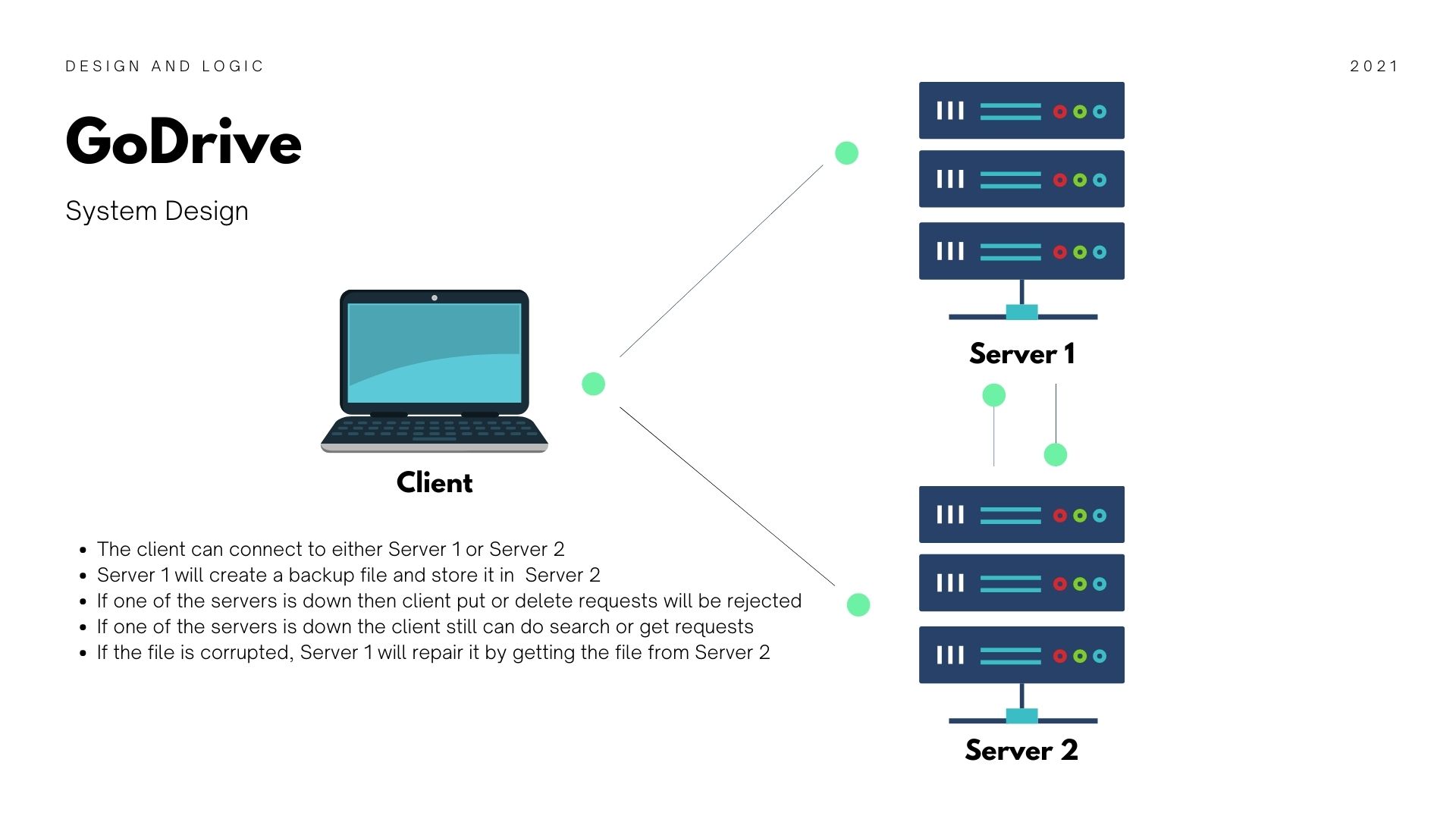
Architecture

Cloud components:
- tunnel-cloud: Maintains a persistent network connection to
tunnel-edgeservices. Supports TCP/HTTP/HTTPS network proxies. - application-grid controller: A Kubernetes CRD controller as part of ServiceGroup. It manages DeploymentGrids and ServiceGrids CRDs and control applications and network traffic on edge worker nodes.
- edge- admission: Assists Kubernetes controllers by providing real-time health check status from
edge-healthservices distributed on all edge worker nodes.
Edge components:
- lite-apiserver: Lightweight kube-apiserver for edge autonomy. It caches and proxies edge components' requests and critical events to cloud kube-apiserver.
- edge-health: Monitors the health status of edge nodes in the same edge region.
- tunnel-edge: Maintains persistent connection to
tunnel-cloudto retrieve API requests to the controllers on the edge. - application-grid wrapper: Managed by
application-grid controllerto provide independent internal network space for services within the same ServiceGrid.
Quickstart Guide
For installation, deployment, and administration, see our Tutorial.
Contact
For any question or support, feel free to contact us via:
- Slack
- Discussion Forum
- WeChat Group

Contributing
Welcome to contribute and improve SuperEdge

![[Question]边缘节点tunnel-edge反复重启,且无法正常查看pod日志及无法SSH连接](https://avatars.githubusercontent.com/u/3113623?v=4)










![[Question] /tmp Permission changed after running edgeadm addon edge-apps](https://avatars.githubusercontent.com/u/7931370?v=4)



![[Question] CNCF SIG-Runtime Discussion/Presentation?](https://avatars.githubusercontent.com/u/7659560?v=4)

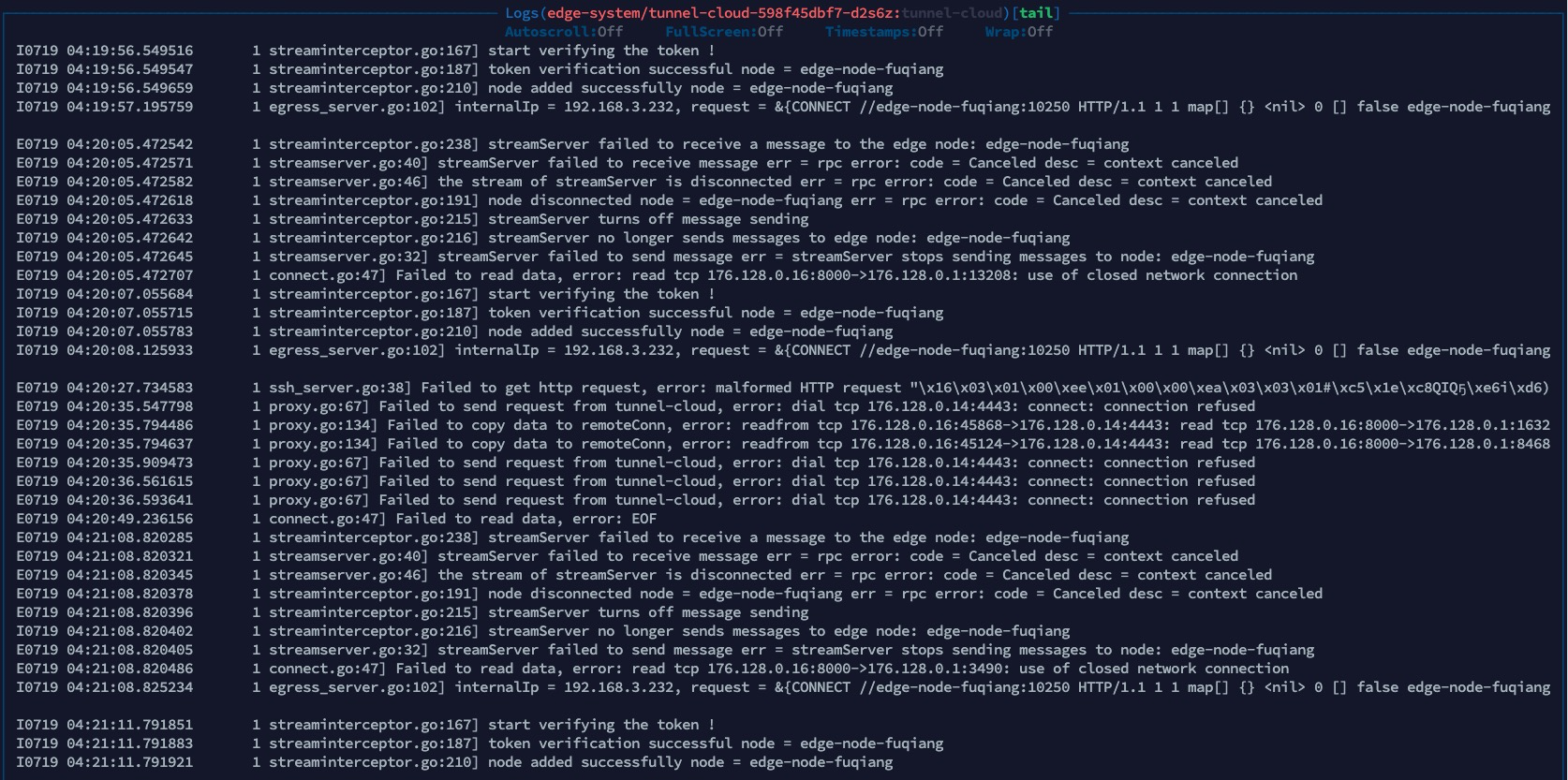
 而在lg-edgedev-38的服务器上,10250 的端口是开的
而在lg-edgedev-38的服务器上,10250 的端口是开的
 同样的yaml 在superEdge0.7.0 上部署deployment 是正常的,请问大佬们这个要怎么解决?
@dodiadodia,@malc0lm ,@00pf00
同样的yaml 在superEdge0.7.0 上部署deployment 是正常的,请问大佬们这个要怎么解决?
@dodiadodia,@malc0lm ,@00pf00
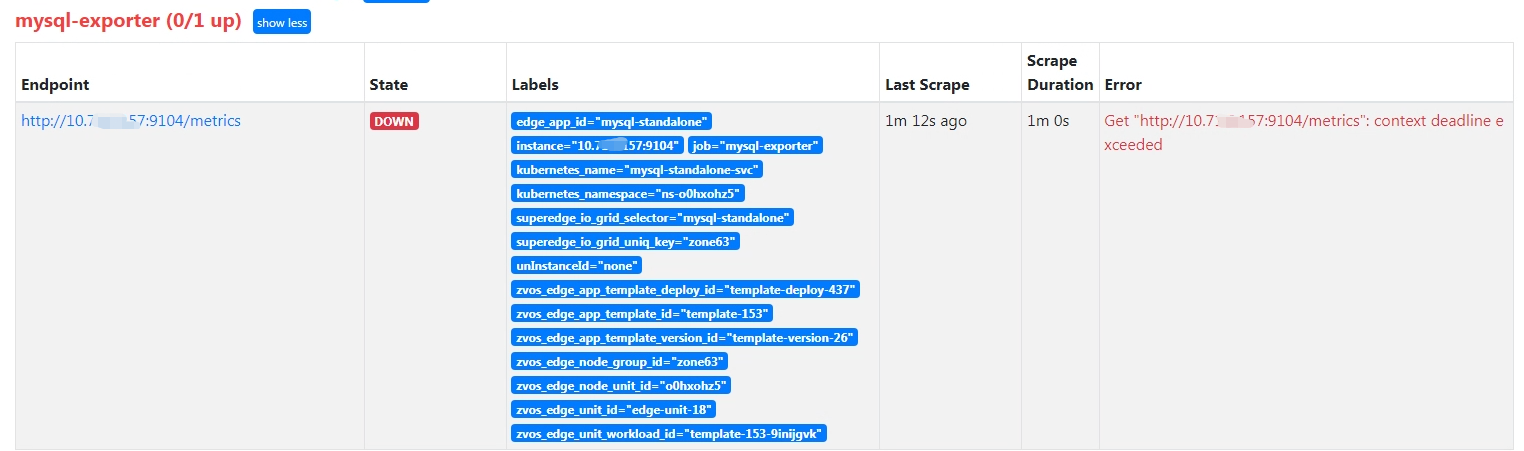
![[Question] Prometheus采集不到边端mysql exporter数据](https://avatars.githubusercontent.com/u/40260032?v=4)





![[Question]the edge-coredns has issue of resolve dns](https://avatars.githubusercontent.com/u/6767972?v=4)