OpenAIOS vGPU scheduler for Kubernetes
![]()

English version|中文版
Introduction
4paradigm k8s vGPU scheduler is an "all in one" chart to manage your GPU in k8s cluster, it has everything you expect for a k8s GPU manager, including:
GPU sharing: Each task can allocate a portion of GPU instead of a whole GPU card, thus GPU can be shared among multiple tasks.
Device Memory Control: GPUs can be allocated with certain device memory and have made it that it does not exceed the boundary.
Virtual Device memory: You can oversubscribe GPU device memory by using host memory as its swap.
Easy to use: You don't need to modify your task yaml to use our scheduler. All your GPU jobs will be automatically supported after installation.
The k8s vGPU scheduler is based on retaining features of 4paradigm k8s-device-plugin (4paradigm/k8s-device-plugin), such as splitting the physical GPU, limiting the memory, and computing unit. It adds the scheduling module to balance the GPU usage across GPU nodes. In addition, it allows users to allocate GPU by specifying the device memory and device core usage. Furthermore, the vGPU scheduler can virtualize the device memory (the used device memory can exceed the physical device memory), run some tasks with large device memory requirements, or increase the number of shared tasks. You can refer to the benchmarks report.
When to use
- Scenarios when pods need to be allocated with certain device memory usage or device cores.
- Needs to balance GPU usage in cluster with mutiple GPU node
- Low utilization of device memory and computing units, such as running 10 tf-servings on one GPU.
- Situations that require a large number of small GPUs, such as teaching scenarios where one GPU is provided for multiple students to use, and the cloud platform that provides small GPU instance.
- In the case of insufficient physical device memory, virtual device memory can be turned on, such as training of large batches and large models.
Prerequisites
The list of prerequisites for running the NVIDIA device plugin is described below:
- NVIDIA drivers ~= 384.81
- nvidia-docker version > 2.0
- Kubernetes version >= 1.16
- glibc >= 2.17
- kernel version >= 3.10
- helm
Quick Start
Preparing your GPU Nodes
The following steps need to be executed on all your GPU nodes. This README assumes that both the NVIDIA drivers and nvidia-docker have been installed.
Note that you need to install the nvidia-docker2 package and not the nvidia-container-toolkit.
You will need to enable the NVIDIA runtime as your default runtime on your node. We will be editing the docker daemon config file which is usually present at /etc/docker/daemon.json:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
if
runtimesis not already present, head to the install page of nvidia-docker
Then, you need to label your GPU nodes which can be scheduled by 4pd-k8s-scheduler by adding "gpu=on", otherwise, it cannot be managed by our scheduler.
kubectl label nodes {nodeid} gpu=on
Download
Once you have configured the options above on all the GPU nodes in your cluster, remove existing NVIDIA device plugin for Kubernetes if it already exists. Then, you need to clone our project, and enter deployments folder
$ git clone https://github.com/4paradigm/k8s-vgpu-scheduler.git
$ cd k8s-vgpu-scheduler/deployments
Set scheduler image version
Check your Kubernetes version by the using the following command
kubectl version
Then you need to set the Kubernetes scheduler image version according to your Kubernetes server version key scheduler.kubeScheduler.image in deployments/values.yaml file , for example, if your cluster server version is 1.16.8, then you should change image version to 1.16.8
scheduler:
kubeScheduler:
image: "registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.16.8"
Enabling vGPU Support in Kubernetes
You can customize your installation by adjusting configs.
After checking those config arguments, you can enable the vGPU support by the following command:
$ helm install vgpu vgpu -n kube-system
You can verify your installation by the following command:
$ kubectl get pods -n kube-system
If the following two pods vgpu-device-plugin and vgpu-scheduler are in Running state, then your installation is successful.
Running GPU Jobs
NVIDIA vGPUs can now be requested by a container using the nvidia.com/gpu resource type:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 vGPUs
nvidia.com/gpumem: 3000 # Each vGPU contains 3000m device memory (Optional,Integer)
nvidia.com/gpucores: 30 # Each vGPU uses 30% of the entire GPU (Optional,Integer)
You should be cautious that if the task can't fit in any GPU node(ie. the number of nvidia.com/gpu you request exceeds the number of GPU in any node). The task will get stuck in pending state.
You can now execute nvidia-smi command in the container and see the difference of GPU memory between vGPU and real GPU.
WARNING: if you don't request vGPUs when using the device plugin with NVIDIA images all the vGPUs on the machine will be exposed inside your container.
Upgrade
To Upgrade the k8s-vGPU to the latest version, all you need to do is restart the chart. The latest version will be downloaded automatically.
$ helm uninstall vgpu -n kube-system
$ helm install vgpu vgpu -n kube-system
Uninstall
helm uninstall vgpu -n kube-system
Scheduling
Current schedule strategy is to select GPU with the lowest task. Thus balance the loads across mutiple GPUs
Benchmarks
Three instances from ai-benchmark have been used to evaluate vGPU-device-plugin performance as follows
| Test Environment | description |
|---|---|
| Kubernetes version | v1.12.9 |
| Docker version | 18.09.1 |
| GPU Type | Tesla V100 |
| GPU Num | 2 |
| Test instance | description |
|---|---|
| nvidia-device-plugin | k8s + nvidia k8s-device-plugin |
| vGPU-device-plugin | k8s + VGPU k8s-device-plugin,without virtual device memory |
| vGPU-device-plugin(virtual device memory) | k8s + VGPU k8s-device-plugin,with virtual device memory |
Test Cases:
| test id | case | type | params |
|---|---|---|---|
| 1.1 | Resnet-V2-50 | inference | batch=50,size=346*346 |
| 1.2 | Resnet-V2-50 | training | batch=20,size=346*346 |
| 2.1 | Resnet-V2-152 | inference | batch=10,size=256*256 |
| 2.2 | Resnet-V2-152 | training | batch=10,size=256*256 |
| 3.1 | VGG-16 | inference | batch=20,size=224*224 |
| 3.2 | VGG-16 | training | batch=2,size=224*224 |
| 4.1 | DeepLab | inference | batch=2,size=512*512 |
| 4.2 | DeepLab | training | batch=1,size=384*384 |
| 5.1 | LSTM | inference | batch=100,size=1024*300 |
| 5.2 | LSTM | training | batch=10,size=1024*300 |
Test Result: 

To reproduce:
- install k8s-vGPU-scheduler,and configure properly
- run benchmark job
$ kubectl apply -f benchmarks/ai-benchmark/ai-benchmark.yml
- View the result by using kubctl logs
$ kubectl logs [pod id]
Features
- Specify the number of vGPUs divided by each physical GPU.
- Limits vGPU's Device Memory.
- Allows vGPU allocation by specifying device memory
- Limits vGPU's Streaming Multiprocessor.
- Allows vGPU allocation by specifying device core usage
- Zero changes to existing programs
Experimental Features
-
Virtual Device Memory
The device memory of the vGPU can exceed the physical device memory of the GPU. At this time, the excess part will be put in the RAM, which will have a certain impact on the performance.
Known Issues
- Currently, A100 MIG is not supported
- Currently, only computing tasks are supported, and video codec processing is not supported.
TODO
- Support video codec processing
- Support Multi-Instance GPUs (MIG)
Tests
- TensorFlow 1.14.0/2.4.1
- torch 1.1.0
- mxnet 1.4.0
- mindspore 1.1.1
The above frameworks have passed the test.
Issues and Contributing
- You can report a bug, a doubt or modify by filing a new issue
- If you want to know more or have ideas, you can participate in the Discussions and the slack exchanges
Authors
- Mengxuan Li ([email protected])
- Zhaoyou Pei ([email protected])
- Guangchuan Shi ([email protected])
- Zhao Zheng ([email protected])

![[4pdvGPU ERROR (pid:167 thread=140191321859904 multiprocess_memory_limit.c:455)]: Failed to lock shrreg: 4](https://avatars.githubusercontent.com/u/33601088?v=4)


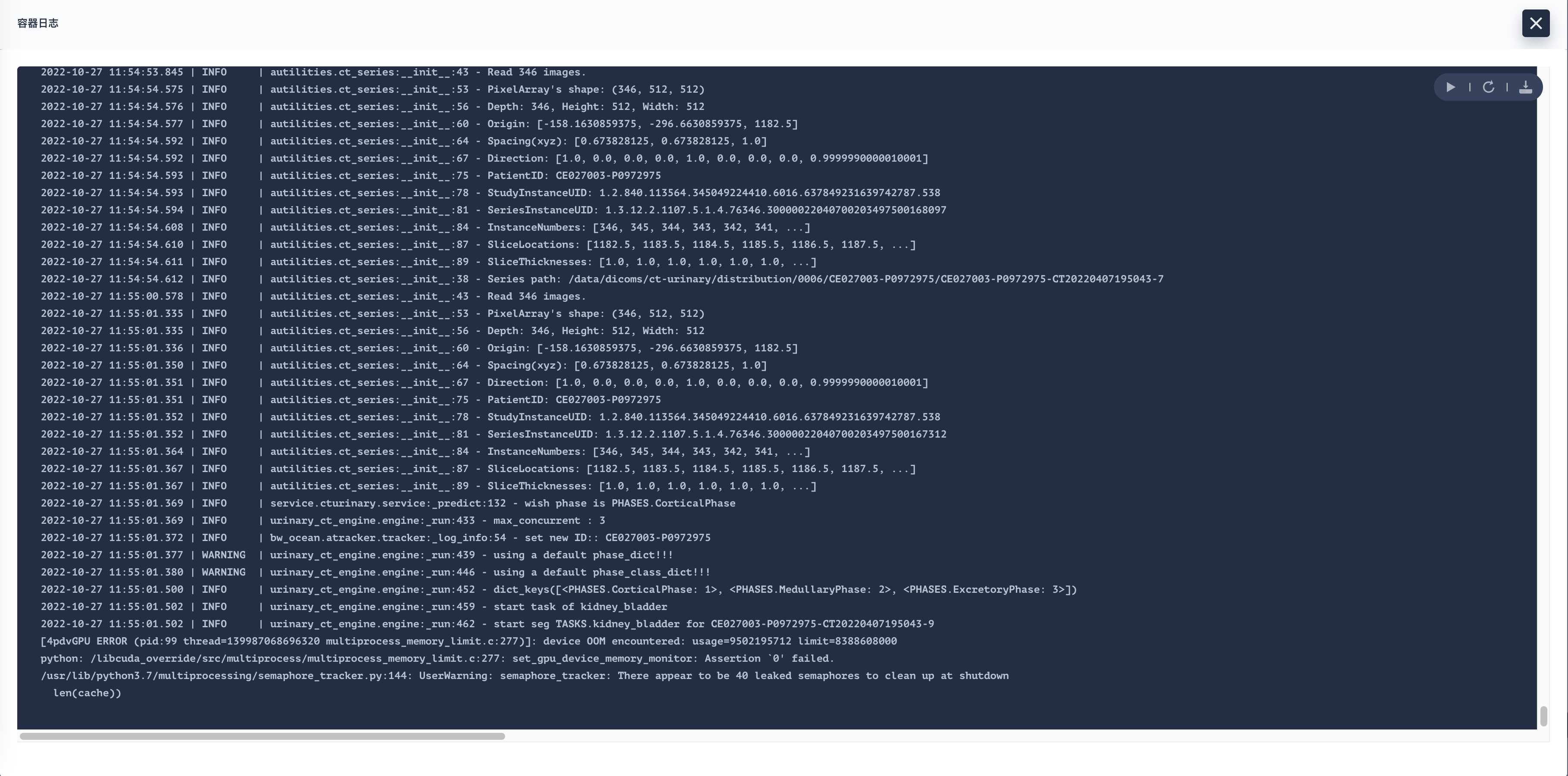
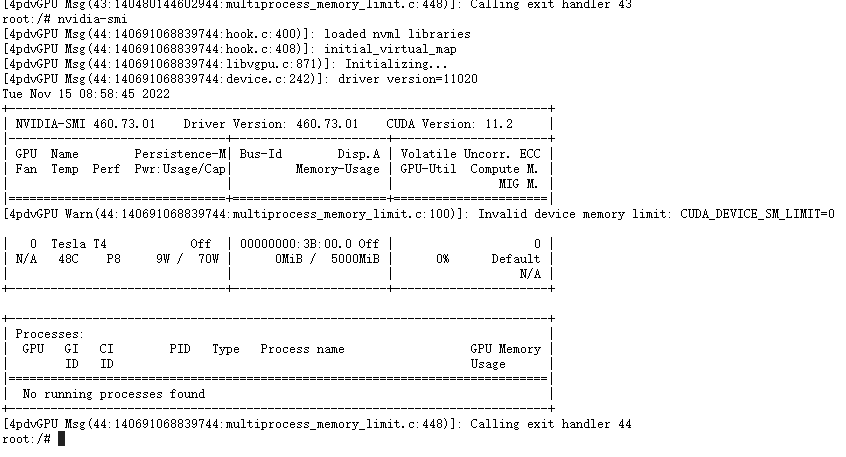 请问一下,我在容器中使用的时候,会报很多warning,但是GPU是能正常使用的,安装命令如下
请问一下,我在容器中使用的时候,会报很多warning,但是GPU是能正常使用的,安装命令如下




 其他的Kubernetes服務也都可以正常佈署
其他的Kubernetes服務也都可以正常佈署