skweez
skweez (pronounced like "squeeze") spiders web pages and extracts words for wordlist generation.
It is basically an attempt to make a more operator-friendly version of CeWL. It is written in Golang, making it far more portable and performant than Ruby.
Build / Install
Binary Releases
You may use binary releases from the release section for your favorite operating system.
Build from source
Assuming you have Go 1.16+ installed and working, just clone the repo and do a go build or use go get github.com/edermi/skweez.
Usage
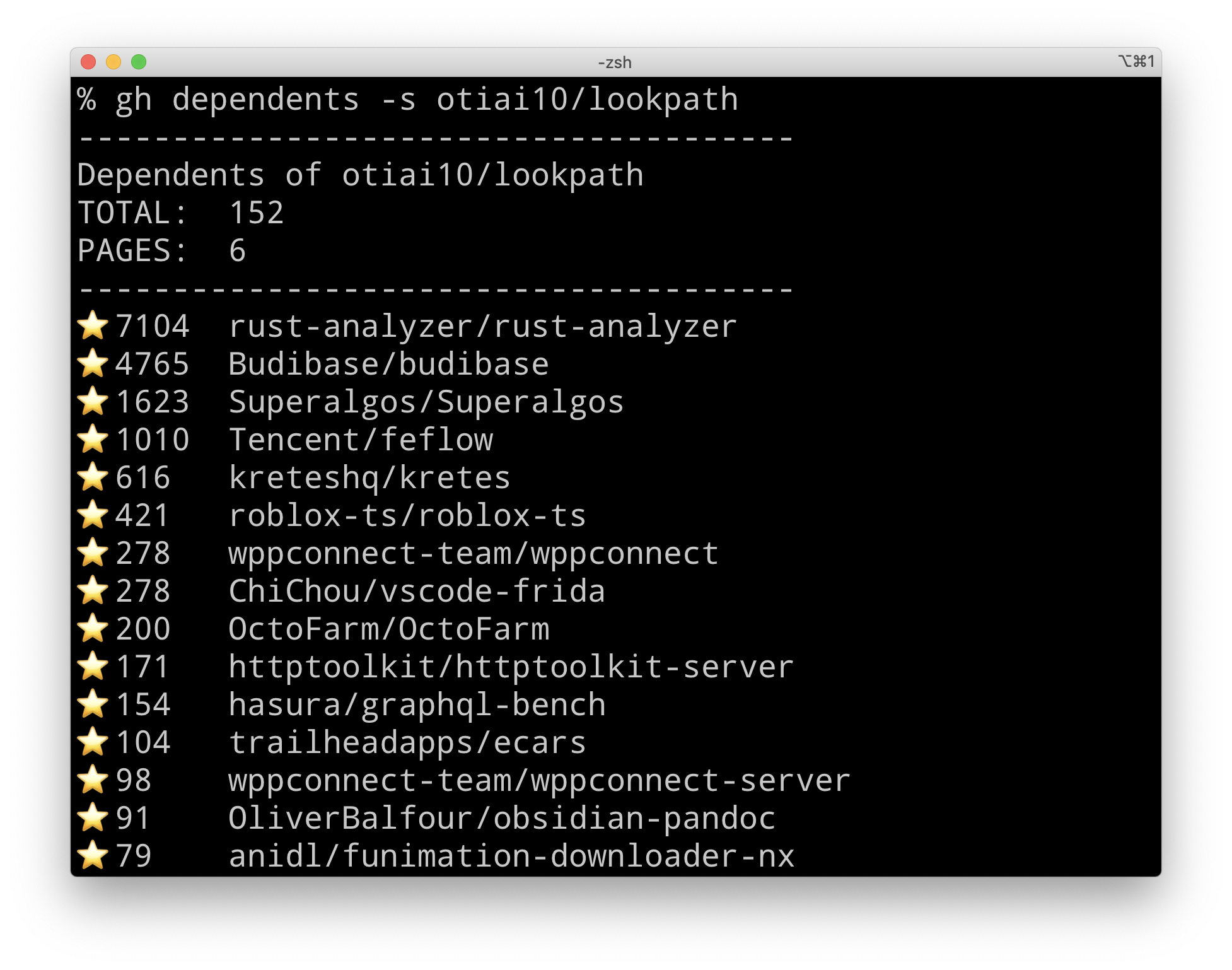
./skweez -h
skweez is a fast and easy to use tool that allows you to (recursively)
crawl websites to generate word lists.
Usage:
skweez domain1 domain2 domain3 [flags]
Flags:
--debug Enable Debug output
-d, --depth int Depth to spider. 0 = unlimited, 1 = Only provided site, 2... = specific depth (default 2)
-h, --help help for skweez
--json Write words + counts in a json file. Requires --output/-o
-n, --max-word-length int Maximum word length (default 24)
-m, --min-word-length int Minimum word length (default 3)
--no-filter Do not filter out strings that don't match the regex to check if it looks like a valid word (starts and ends with alphanumeric letter, anything else in between). Also ignores --min-word-length and --max-word-length
-o, --output string When set, write an output file to
.txt (
.json when --json is specified). Empty writes no output to disk
--scope strings Additional site scope, for example subdomains. If not set, only the provided site's domains are in scope
skweez takes an arbitrary number of links and crawls them, extracting the words. skweez will only crawl sites under the link's domain, so if you submit www.somesite.com, it will not visit for example blog.somesite.com even if there are links present. You may provide a list of additionally allowed domains for crawling via --scope.
./skweez https://en.wikipedia.org/wiki/Sokushinbutsu -d 1
19:07:44 Finished https://en.wikipedia.org/wiki/Sokushinbutsu
There
learned
Edit
Alternate
mantra
Sokushinbutsu
36–37
Pseudoapoptosis
Necrophilia
information
mummification
many
identifiers
reducing
range
threat
popular
Honmyō-ji
Republic
Dignified
Recent
Himalayan
Burning
cause
Last
Español
honey
Siberia
That
Megami
Karyorrhexis
have
practically
1962
Forensic
Magyar
[...]
skweez is pretty fast. It crawls several pages a second, the example Wikipedia article above with default settings (depth=2) takes skweez 38 seconds to crawl over 360 Wikipedia sites and generates a dictionary of > 109.000 unique words.
skweez allows you to write the results into a file, if you chose JSON, you will also get the count for each word. I recommend jq for working with JSON.
In order to improve result quality, skweez has a builtin regex to filter out strings that do not look like words. --no-filter disables this behavior. skweez only selects words in length between 3 and 24 - you can override this behavior with --min-word-length and --max-word-length.
Bugs, Feature requests
Just file a new issue or, even better, submit a PR and I will have a look.
Future improvements
These are just ideas, I don't have plans of implementing them now since I usually don't need them.
- Features CeWL provides (E-Mail filtering, proxy auth, custom headers, custom user agent)
- Better performance
- More control over what's getting scraped
License
GPL, see LICENSE file.